

from datetime import datetime,timedelta,date
days = {0: u"Понедельник", 1: u"Вторник", 2: u"Среда", 3: u"Четверг", 4: u"Пятница", 5: u"Суббота", 6: u"Воскресенье"}
firstDate = '31122020'
secondDate = '01012012'
f_date = datetime.strptime(firstDate,'%d%m%Y').date()
s_date = datetime.strptime(secondDate,'%d%m%Y').date()
dates_2020 = []
delta = timedelta(days=1)
while s_date <= f_date:
s_date += delta
dates_2020.append(days[s_date.weekday()] + ':' + s_date.strftime('%m.%d'))
for i in dates_2020:
print(i)Четверг:12.24
Пятница:12.25
Суббота:12.26
Воскресенье:12.27
Понедельник:12.28
Вторник:12.29
Среда:12.30
Четверг:12.31
from datetime import datetime
RU_MONTH_VALUES = {
'Январь': 1,
'Февраль': 2,
'Март': 3,
'Апрель': 4,
'Май': 5,
'Июнь': 6,
'Июль': 7,
'Август': 8,
'Сентябрь': 9,
'Октябрь': 10,
'Ноябрь': 11,
'Декабрь': 12,
}
def int_value_from_ru_month(date_str):
for k, v in RU_MONTH_VALUES.items():
date_str = date_str.replace(k, str(v))
return date_str
date_str = int_value_from_ru_month('1 Декабрь 2019')
print (date_str)
d = datetime.strptime(date_str, '%d %m %Y')
print(d)
pip3 install dateparserimport dateparser
ruDate = '1 Декабрь 2019'
pyDate = dateparser.parse(ruDate)
print(pyDate)from mega import Mega
mega = Mega()
m = mega.login('почта', 'пароль')
details = m.get_user()
print(details)import random
i = round(random.uniform(0.1, 1.0), 10)
print("%.1f" % i)import файл
from файл import что-то
from файл import * # Импорт всего - не рекомендуется.bot.reply_to(message, 'something fails...') - не делайте так никогда, в смысле в разных участках кода выводить одну и ту же общую ошибку с одинаковым текстом. У вас в коде один текст для четырёх разных ошибок. И как гадать, когда в телегу пришло сообщение "something fails..." - из какого места в коде прилетела ошибка. Плюс, как мне кажется, не нужно обрабатывать все исключения одним кодом. Лучше написать обработчики для каждого возможного исключения, и выводить конкретный текст ошибки в случае определенного исключения, и при возможности как-то обрабатывать его.
import telebot
from PIL import Image
from PIL import ImageDraw
from PIL import ImageFont
token = 'Здесь нужно вписать токен вашего бота'
bot = telebot.TeleBot(token)
def generate_doc(first_name, second_name):
img = Image.open('1.jpg')
font = ImageFont.truetype('font.ttf',30) # Загрузка шрифта и установка размера
font_color = (74,75,69) # Цвет шрифта
first_name_pos = (585,172) # Координаты первой буквы фамилии на картинке 1.jpg
second_name_pos = (505,205) # Координаты первой буквы имени
drawing = ImageDraw.Draw(img)
drawing.text(first_name_pos,first_name,font=font,fill=font_color)
drawing.text(second_name_pos,second_name,font=font,fill=font_color)
return img
@bot.message_handler(content_types=['text'])
def repeat_all_message(message):
string = message.text
s = string.split(' ')
if len(s) == 3:
image = generate_doc(s[0],s[1]+' '+s[2])
image.save('test.jpg')
bot.send_photo(message.chat.id,photo=open('test.jpg','rb'))
else:
bot.send_message(message.chat.id,'Ошибка! Введите имя, фамилию и отчество через пробел.')
if __name__ == '__main__':
bot.polling(none_stop=True)
bot = telebot.TeleBot(config.token)import telebot
import pyowm
owm = pyowm.OWM('key', language = "ru")
bot = telebot.TeleBot('token')
@bot.message_handler(content_types=['text'])
def send_echo(message):
try:
observation = owm.weather_at_place( message.text )
w = observation.get_weather()
temp = w.get_temperature('celsius')["temp"]
hum = w.get_humidity()
time = w.get_reference_time(timeformat='iso')
wind = w.get_wind()["speed"]
answer ="В городе " + message.text + " сейчас " + w.get_detailed_status() + "\n"
answer += "Температура сейчас в районе " + str(temp) + "\n\n" + "\nСкорость ветра: " + str(wind) + "м/с" + "\n" + "\nВлажность: " + str(hum) + "%" + "\n" + "\nВремя: " + str(time) + "\n"
if temp < 11:
answer += "Сейчас очень холодно."
elif temp < 20:
answer += "Сейчас прохладно, лучше одеться потеплее."
else:
answer += "Температура в норме!"
bot.send_message(message.chat.id, answer)
except pyowm.exceptions.api_response_error.NotFoundError:
bot.send_message(message.chat.id,'Ошибка! Город не найден.')
except pyowm.exceptions.api_response_error.UnauthorizedError:
print('Не верный ключ pyowm!')
bot.polling( none_stop = True)
input()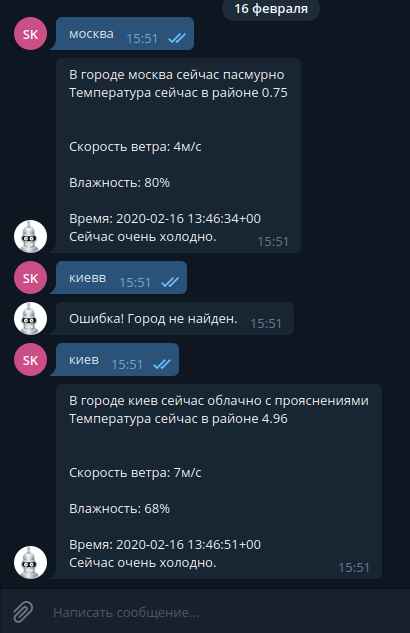
pip install example, вы устанавливаете пакет из репозитория pypi.org.pip install ./dist/ProjectName.tar.gz
import requests
from bs4 import BeautifulSoup
from lxml import html
import csv
url = 'https://www.yoox.com/ru/%D0%B4%D0%BB%D1%8F%20%D0%BC%D1%83%D0%B6%D1%87%D0%B8%D0%BD/%D0%BE%D0%B4%D0%B5%D0%B6%D0%B4%D0%B0/shoponline#/dept=clothingmen&gender=U&page=1&season=X'
headers = {'user-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:72.0) Gecko/20100101 Firefox/72.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'
}
def getClothes(url,page_id):
clothes = []
respones = requests.get(url,headers=headers)
soup = BeautifulSoup(respones.text,'lxml')
mainContent = soup.find('div',id=f'srpage{page_id}')
products = mainContent.find_all('div',class_='col-8-24')
for product in products:
brand = product.find('div',class_='itemContainer')['data-brand'] # Бренд
cod10 = product.find('div',class_='itemContainer')['data-current-cod10'] # Для формирования ссылки yoox.com/ru/{cod10}/item
category = product.find('div',class_='itemContainer')['data-category'] # Категория
oldPrice = product.find('span',class_='oldprice text-linethrough text-light') # Старая цена (может не быть)
newPrice = product.find('span',class_='newprice font-bold') # Новая цена (может не быть)
if oldPrice is not None:
# Данный код выполняется только, если на товар есть скидка
sizes = product.find_all('div',class_='size text-light')
str_sizes = ''
for x in sizes:
str_sizes += x.text.strip().replace('\n',';')
clothes.append({'art':cod10,
'brand':brand,
'category':category,
'url':f'https://yoox.com/ru/{cod10}/item',
'oldPrice':oldPrice.text,
'newPrice':newPrice.text,
'sizes':str_sizes
})
return clothes
def getLastPage(url):
respones = requests.get(url,headers=headers)
soup = BeautifulSoup(respones.text,'lxml')
id = soup.find_all('li', class_ = 'text-light')[2]
return int(id.a['data-total-page']) + 1
def writeCsvHeader():
with open('yoox_man_clothes.csv', 'a', newline='') as file:
a_pen = csv.writer(file)
a_pen.writerow(('Артикул', 'Ссылка', 'Размеры', 'Бренд', 'Категория', 'Старая цена', 'Новая цена'))
def files_writer(clothes):
with open('yoox_man_clothes.csv', 'a', newline='') as file:
a_pen = csv.writer(file)
for clothe in clothes:
a_pen.writerow((clothe['art'], clothe['url'], clothe['sizes'], clothe['brand'], clothe['category'], clothe['oldPrice'], clothe['newPrice']))
if __name__ == '__main__':
writeCsvHeader() # Запись заголовка в csv файл
lastPage = getLastPage(url) # Получаем последнею страницу
for x in range(1,lastPage): # Вместо 1 и lastPage можно указать диапазон страниц. Не начинайте парсить с нулевой страницы!
print(f'Скачавается: {x} из {lastPage-1}')
url = f'https://www.yoox.com/RU/shoponline?dept=clothingmen&gender=U&page={x}&season=X&clientabt=SmsMultiChannel_ON%2CSrRecommendations_ON%2CNewDelivery_ON%2CRecentlyViewed_ON%2CmyooxNew_ON'
files_writer(getClothes(url,x)) # Парсим и одновременно заносим данные в csv
import requests
from bs4 import BeautifulSoup
url = 'https://qna.habr.com/search?q='
def search(keyword):
responce = requests.get(url+keyword)
soup = BeautifulSoup(responce.text,"html.parser")
try:
contents = soup.find_all('li',class_='content-list__item')
for answers in contents:
title = answers.find('a',class_='question__title-link question__title-link_list').text.strip()
count = answers.find('div',class_='mini-counter__count mini-counter__count_grey').text.strip()
print(f'{title} {count}')
except:
pass
keyword = input('Введите запрос: ')
search(keyword)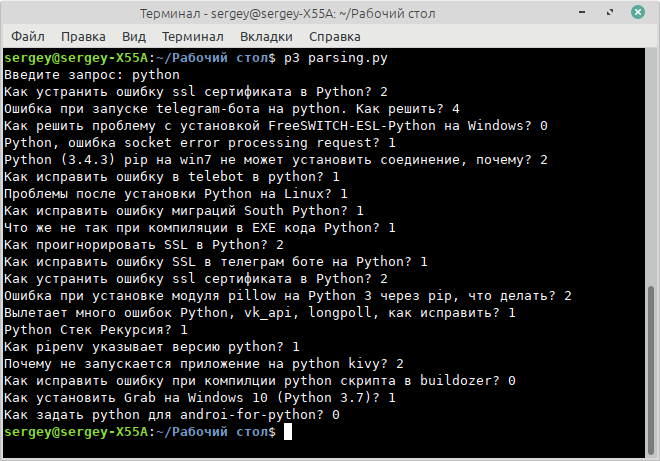
{kind=link}