Wataru, после починки push_back вариант без result все равно оказывается чуточку быстрее, несмотря на, казалось бы, лишнее копирование - за счет лучшей локальности данных, как я понимаю.
Впрочем, это уже сильно зависит от того, что хранится в векторе.
Более того, использование push_back создает для компилятора две интересные беды (см. бенч)
1) На каждый push_back он будет вынужден делать проверку, а не кончилось ли место в векторе.
2) Будет труднее применить оптимизацию при помощи векторных инструкций процессора.
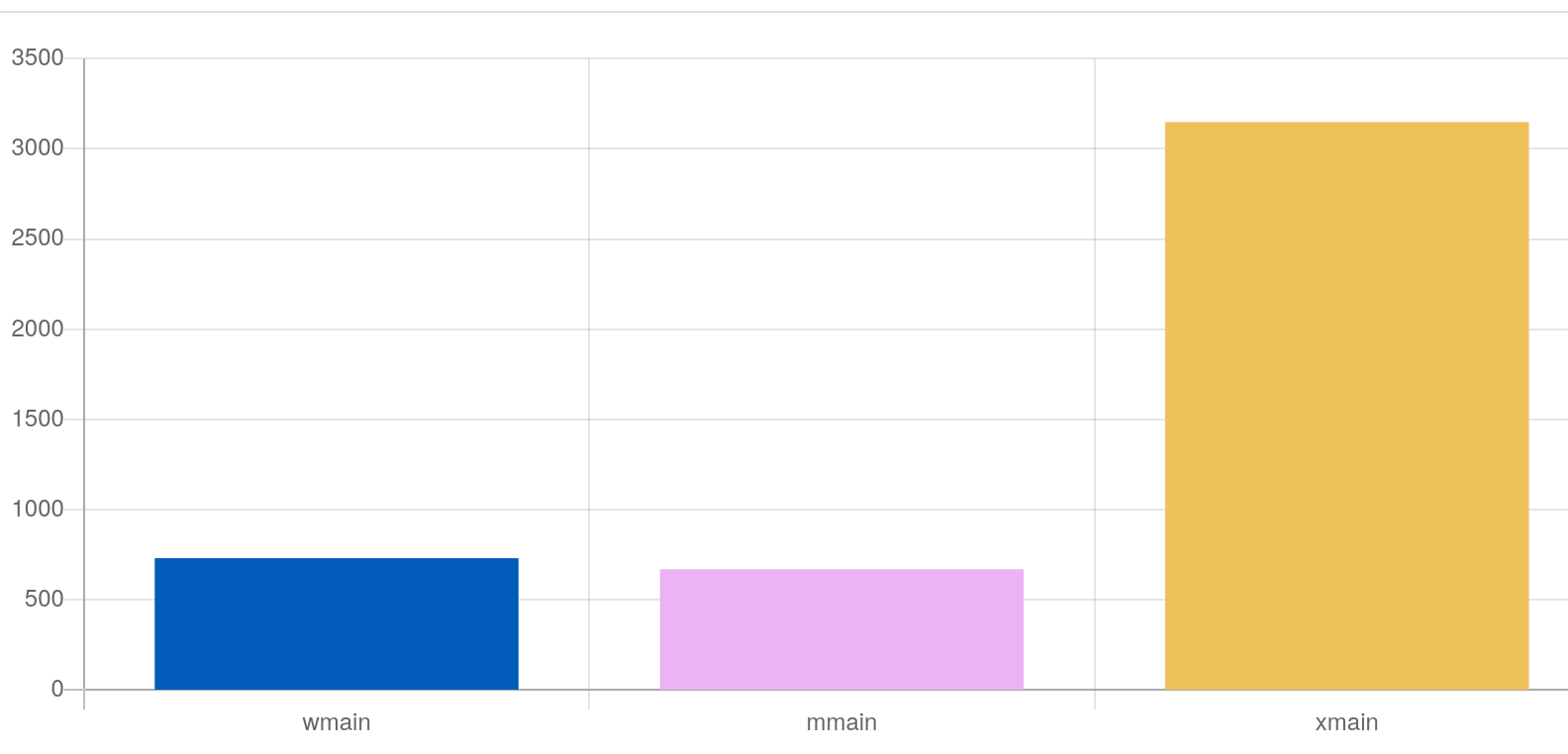
Желтый столбик - это вариант с push_back и он очень сильно болен
Синий столбик - это ваш исправленный вариант, в котором убран push_back
Розовый - мой вариант, как в ответе.
Копирования вектора лишний раз не будет, будет перемещение. Так что произойдет три new и три delete (см дизасм).
Что касается того, что быстрее, сначала скопировать, потом суммировать, или просто суммировать, здесь тоже есть нюанс - если данные сначала скопировать, их локальность будет выше при последующем суммировании.
(По крайней мере, мой вариант порождает более короткий выхлоп в машинном коде)
magnetik1000, три варианта
1) шаги сделаны неверно
2) вы не понимаете, что параметры полностью сбросились и девайс нужно настраивать заново
3) он действительно сломался.
Wataru, Строки компилятор перетряхивает - у gcc есть настройка, как интерпретировать кодировку исходников. Например, это важно нля литералов типа u8"строка, которая будет загнана в utf8"
Очевидно, что дело в локали, а не в коде - компилятор преобразует строку в транслит. Чтобы в этом убедиться, достаточно влезть в бинарник и увидеть там уже транслитерированные строки.
nnkjc, у вас нет возможности на это повлиять, на самом деле. Ну скачиваете вы торрент с машины, где стоит лимит на скачивание в 300 килобит - 300 килобит вы и получите. Это не зависит от вас.
Про одну пару и 10 мегабит интересно - это какой стандарт? 10 Мегабит на коаксиале я помню, а вот чтобы по одной витой паре было 10 - такого не помню. 10BASE-T все же по двум парам бегало.
Лучше в таких вопросах указывать больше подробностей - какая задача решается, откуда берется сигнал, какая нагрузка. Иначе все превратится в проблему X-Y
Adamos, такие простыни прекрасно существуют и в наше время - в виде очередного ML - проекта на питончике или трех-пяти километров бизнес-логики на нем же.
Присутствуют те же действующие лица - единственный класс, в который навалено все, имена пременных вида a, b, c, d (Потому что в тетратке у Чуня в формулах именно эти буквы), 0 штук комментариев - или другой вариант, любовно напиханные комментарии уровня Кэпа, но датировка их обычно относится к первому-второму дню разработки. Потом полезли баги и стало не до комментирования.
К счастью, благодаря современному активному впихиванию git, к способом понимания таких текстов добавляются компаративные методы из лингвистики - можно в динамике смотреть, куда двигалась мысль автора, а не быть свидетелем уже свершивсегося факта.
Adamos, Опять же, когда на предприятии люди заняты не своим делом - это вызывает вопросы. Инженер может поставить задачу разработчику, может написать какой-то референс или пример. Но код из-под непрограммиста плохо живет как часть программного продукта (не важно, внутреннего или коммерческого) - именно из-за невозможности рефакторинга, отсутствия деления на модули и полного игнорирования SOLID и KISS.
Любая доработка такого чуда приводит к непредсказуемым последствиям и может занимать непредсказуемое время - кстати, именно эти характеристики почему-то требуют от программиста чаще всего.
pfg21, Современные ноутбуки обычно питаются по TYPE-C, который как раз и является хитроумным интерфейсом. С потребительсткой точки зрения, это лучше, так как провода такие продаются в любой забегаловке, да и изнашивается и ломается как правило именно провод.
В отличие от случаев выломанных гнезд-бочек (иногда вместе с трезинами в материнке)