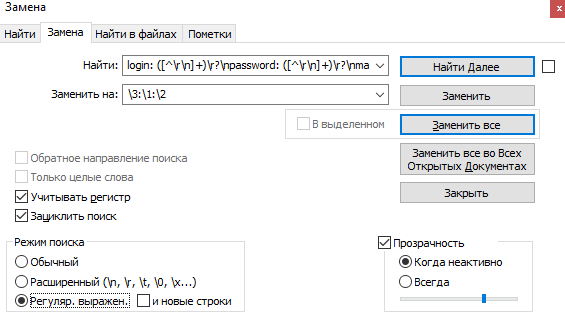
^(19[0-9]{2}|20[0-9]{2}|2100)$let regex = /^(19[0-9]{2}|20[0-9]{2}|2100)$/;
let test = regex.test("2000"); // возвращает true
let test2 = regex.test("1899"); // возвращает false^(199[0-9]|20[0-9]{2}|2100)$
\b(\d[\d\w.-]*)\b(\d[^ ]*)preg_match('/\b(\d[^ ]*)/', $product->name, $matches);import re
data = """
1 ) София Захарова : 322 221 929 монет
2 ) Диана Зайцева : 123 543 монеты
3 ) Семен Соколов : 199 монет
4 ) Вадим Новиков : 18 монет
5 ) Игорь Валеев : 5 монет
"""
# Регулярное выражение для поиска чисел после ":"
pattern = r":\s*([\d\s]+)"
# Поиск всех совпадений
matches = re.findall(pattern, data)
# Преобразование результатов в список чисел
numbers = [int(match.replace(" ", "")) for match in matches]
print(numbers)но она не понимает что такое отрицательные числа, а я не понимаю как заставить ее понимать
-
^7
\s - это любой пробельный символ, включая символ перевода строки.\s, а класс конкретных символов в квадратных скобках. Например, пробелы + символы табуляции. Получится так:[ \t]{2,}
,1, ','_,2,'text',x'word, ''\'\\word2'найти все запятые в этом тексте, кроме тех что в одиночных кавычках
(?:[^,']*'[^']*'[^,']*|[^,']*)(,)(?:[^,']*'[^']*'[^,']*|[^,']*)цель: удалить все запятые из кода, кроме первой
let str = "1,,0,0,";
let arr = str.split(',');
str = arr.splice(0,1) + ',' + arr.join(''); // 1,00
console.log(str);",1,00" или "1", то нужно ещё чуть-чуть переделать, добавив немного кода.
regex = /(?<=:)([a-z0-9_]*)/gi;
если существует любые буквы или буквы + \n или отдельно \n то текст валиден.
^[a-zA-Z]*\n?$/^[a-zA-Z]*\n?$/.test("asd") //true
/^[a-zA-Z]*\n?$/.test("asd\n") //true
/^[a-zA-Z]*\n?$/.test("asd\n\n") //false
/^[a-zA-Z]*\n?$/.test("asd asd") //false
/^[a-zA-Z]*\n?$/.test("123") //false
/^[a-zA-Z]*\n?$/.test("asd123") //false
/^[a-zA-Z]*\n?$/.test("\nasd") //false
/^[a-zA-Z]*\n?$/.test("\n") //true
/^[a-zA-Z]*\n?$/.test("") //true.trim(), чтобы убрать пробельные символы в начале и в конце текста (но не в середине). Это избавит от необходимости помнить, что в конце может быть \n или случайно нажатый пробел (например, при вводе логина или пароля) и т.п.
([^ \n])[^ \n]+ (в начале дописать пробел)\1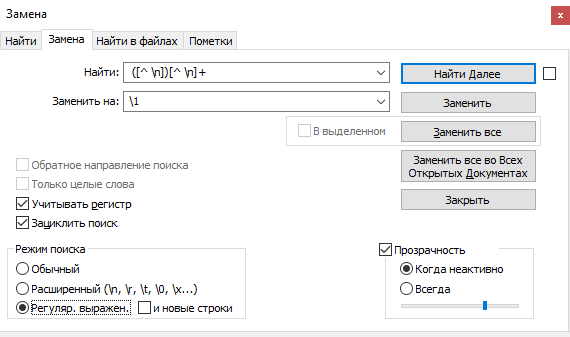
"email":\[([^[\]]+)\]