log = dict()
# перебираем ячейки 1-го столбца и группируем по времени лога
for c in sheet['A']:
key = c.value[:8]
val = c.value[10:]
log[key] = log.get(key,'') + val
print(log)
rc = re.compile(r"(\d+-\d+-\d+) (\d+:\d+:\d+).*?Flow (\d+).*?POS:.*?(\d+)")
print(rc)
new_data = []
for key, val in log.items():
m = rc.search(val)
if m:
new_data.append(m.groups())
# наши разбитые данные
print('new data:', new_data)
# и записываем результат на новый лист (для простоты через добавление новых строк)
sheet_name = 'Лист2'
if sheet_name not in wb.sheetnames:
wb.create_sheet(sheet_name)
sheet = wb[sheet_name]
for row in new_data:
sheet.append(row)
wb.save('C:\\Users\\OD\\Desktop\\python_scripts\\book1.xlsx')
log = dict()
# перебираем ячейки 1-го столбца и группируем по времени лога
for c in sheet['A']:
key = c.value[:8]
val = c.value[10:]
log[key] = log.get(key,'') + val
rc = re.compile(r"(\d+-\d+-\d+) (\d+:\d+:\d+).*?Flow (\d+).*?POS:.*?(\d+)")
new_data = []
for key, val in log.items():
m = rc.search(val)
if m:
new_data.append(m.groups())
# наши разбитые данные
print('new data:', new_data)
# и записываем результат на новый лист (для простоты через добавление новых строк)
sheet_name = 'Лист2'
if sheet_name not in wb.sheetnames:
wb.create_sheet(sheet_name)
sheet = wb[sheet_name]
sheet = wb['Лист2']
for row in new_data:
sheet.append(row)
wb.save('C:\\Users\\OD\\Desktop\\python_scripts\\book1.xlsx')
new data: []
---------------------------------------------------------------------------
KeyError Traceback (most recent call last) in
23
24 # и записываем результат на новый лист (для простоты через добавление новых строк)
---> 25 sheet = wb['Лист2']
26 for row in new_data:
27 sheet.append(row)
~\Anaconda3\lib\site-packages\openpyxl\workbook\workbook.py in __getitem__(self, key)
275 if sheet.title == key:
276 return sheet
--> 277 raise KeyError("Worksheet {0} does not exist.".format(key))
278
279 def __delitem__(self, key):
log = dict()
# перебираем ячейки 1-го столбца и группируем по времени лога
for c in sheet['A']:
key = c.value[:8]
val = c.value[10:]
log[key] = log.get(key,'') + val
rc = re.compile(r"(\d+-\d+-\d+) (\d+:\d+:\d+).*?Flow (\d+).*?POS:.*?(\d+)")
new_data = []
for key, val in log.items():
m = rc.search(val)
if m:
new_data.append(m.groups())
# наши разбитые данные
print('new data:', new_data)
# и записываем результат на новый лист (для простоты через добавление новых строк)
sheet = wb['Sheet2']
for row in new_data:
sheet.append(row)
wb.save('C:\\Users\\OD\\Desktop\\python_scripts\\Book1.xlsx')
# и в итоге получил это...
new data: []
---------------------------------------------------------------------------
KeyError Traceback (most recent call last) in
23
24 # и записываем результат на новый лист (для простоты через добавление новых строк)
---> 25 sheet = wb['Sheet2']
26 for row in new_data:
27 sheet.append(row)
~\Anaconda3\lib\site-packages\openpyxl\workbook\workbook.py in __getitem__(self, key)
275 if sheet.title == key:
276 return sheet
--> 277 raise KeyError("Worksheet {0} does not exist.".format(key))
278
279 def __delitem__(self, key):
KeyError: 'Worksheet Sheet2 does not exist.'
Написано
Войдите на сайт
Чтобы задать вопрос и получить на него квалифицированный ответ.
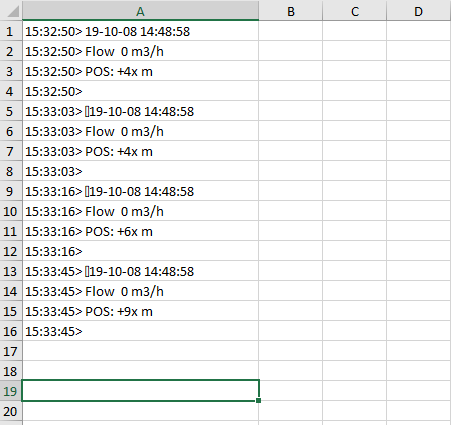
Создает в файле новый Лист2 и в нем пусто все равно. Не могу понять почему не сохраняет ?
import openpyxl
import re
wb = openpyxl.load_workbook('C:\\Users\\OD\\Desktop\\python_scripts\\book1.xlsx')
sheet = wb['Лист1']
log = dict()
# перебираем ячейки 1-го столбца и группируем по времени лога
for c in sheet['A']:
key = c.value[:8]
val = c.value[10:]
log[key] = log.get(key,'') + val
print(log)
rc = re.compile(r"(\d+-\d+-\d+) (\d+:\d+:\d+).*?Flow (\d+).*?POS:.*?(\d+)")
print(rc)
new_data = []
for key, val in log.items():
m = rc.search(val)
if m:
new_data.append(m.groups())
# наши разбитые данные
print('new data:', new_data)
# и записываем результат на новый лист (для простоты через добавление новых строк)
sheet_name = 'Лист2'
if sheet_name not in wb.sheetnames:
wb.create_sheet(sheet_name)
sheet = wb[sheet_name]
for row in new_data:
sheet.append(row)
wb.save('C:\\Users\\OD\\Desktop\\python_scripts\\book1.xlsx')
Получаем:
{'15:32:50': '19-10-08 14:48:58Flow 0 m3/hPOS: +4x m', '15:33:03': '_x001A_19-10-08 14:48:58Flow 0 m3/hPOS: +4x m', '15:33:16': '_x001A_19-10-08 14:48:58Flow 0 m3/hPOS: +6x m', '15:33:45': '_x001A_19-10-08 14:48:58Flow 0 m3/hPOS: +9x m'}
re.compile('(\\d+-\\d+-\\d+) (\\d+:\\d+:\\d+).*?Flow (\\d+).*?POS:.*?(\\d+)')
new data: []