import requests
from bs4 import BeautifulSoup
import json
HEADERS = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36",
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept - Encoding': 'gzip, deflate, br',
'Accept - Language': 'ru-RU,ru;q=0.9,en-US;q=0.8,en;q=0.7',
'Referer': 'https://jobs.dou.ua/vacancies/?category=Ruby'}
URL = "https://jobs.dou.ua/vacancies/?category=Ruby"
session = requests.Session()
def get_html(url):
r = session.get(url, headers=HEADERS)
return r
def get_links(response):
if response.status_code == 200:
html = BeautifulSoup(response.text, "html.parser")
lis = html.find_all('li', class_="l-vacancy")
# Количество вакансий до нажатия
print(len(lis))
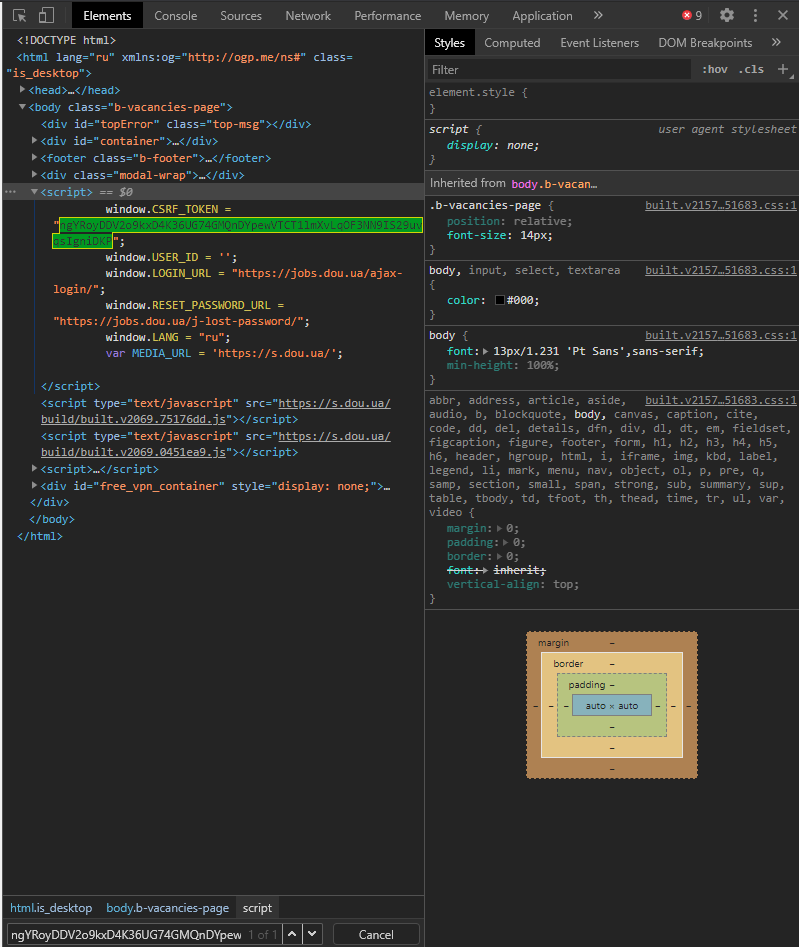
# Костыльно достаю csrf
script = str(html.select('script')[5])
csrf = str(script[32:32+64])
print(script)
print(csrf)
load_data = {
'csrfmiddlewaretoken': csrf,
'count': 20}
response = session.post('https://jobs.dou.ua/vacancies/xhr-load/?category=Ruby', data=load_data)
html = BeautifulSoup(response.text, "html.parser")
lis = html.find_all('li', class_="l-vacancy")
# Количество вакансий после нажатия
print(len(lis))
else:
return 'Connection error!'
get_links(get_html(URL))Количество вакансий до нажатия: 20
script:<script src="https://s.dou.ua/build/built.v2069.75176dd.js" type="text/javascript"></script>
csrf: ild/built.v2069.75176dd.js" type="text/javascript">
Количество вакансий после нажатия: 0
Количество вакансий до нажатия: 20
script:<script> window.CSRF_TOKEN = "FDWmjTJdOi1CHjjIcUbjobYCNr0DFBqMB98TZ0jcCCxHYvejjlWjGPmwlHDQOKoz"; window.USER_ID = ''; window.LOGIN_URL = "https://jobs.dou.ua/ajax-login/"; window.RESET_PASSWORD_URL = "https://jobs.dou.ua/j-lost-password/"; window.LANG = "ru"; var MEDIA_URL = 'https://s.dou.ua/'; </script>
csrf: FDWmjTJdOi1CHjjIcUbjobYCNr0DFBqMB98TZ0jcCCxHYvejjlWjGPmwlHDQOKoz
Количество вакансий после нажатия: 0