Фактически задача сводится к поиску количества совпадений значений каждого атрибута таблицы А со значениями каждого атрибута таблицы Б.
Можно попробовать используя метаданные построить список запросов вида:
select
(select count(*) from A where A.column_name1 in (select B.column_name1 from B )) as column_name1_x_column_name1,
(select count(*) from A where A.column_name1 in (select B.column_name2 from B )) as column_name1_x_column_name2 и т.д.
Пример для postgres:
with B as
(
select table_name, column_name, data_type from information_schema.columns c where c.table_name in ('product') --название таблицы А
)
, common as (
select A.table_name A_table_name, A.column_name A_column_name,
B.table_name B_table_name, B.column_name B_column_name from information_schema.columns as A
inner join B on A.data_type = B.data_type
where A.table_name in ('printer') --название таблицы Б
)
select '(select count(*) from ' || common.A_table_name || ' where ' || common.A_column_name || ' in (select '|| B_column_name || ' from ' || B_table_name || ' )) as ' || A_column_name || '_x_' || B_column_name || ',' from common
Вариант соединения для примера сделан по типам данных.
Далее оборачиваете еще в один select и выполняете.
Получается что-то вроде:
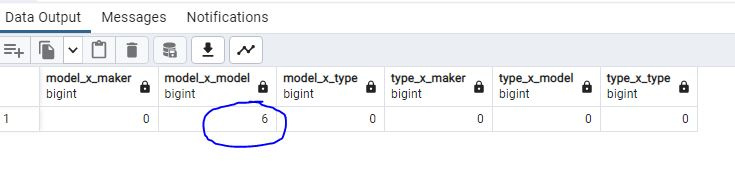
где видно количество совпадений.
Результат, конечно, не означает, что по этим полям можно соединять таблицы. Это могут быть ссылки на таблицу С, например. Или совпадающие даты. Дальше нужно анализировать.
Если правильно понимаю, у автора таблицы с большим количеством столбцов без описания. Так можно хотя бы сузить диапазон поиска.