Я пробовал экспериментировать с поиском через @@ и там действительно нет проблемы с очередностью, но я не нашел возможности искать по части слова (максимум по префиксу, что актуально для всей поисковой фразы а не для каждого слова в отдельности).
Но в этом случае вот эта проблема все еще остается
Lynn «Кофеман», соседние:
- предыдущая - строка с наибольшим ID что меньше ID текущей записи, и type = type текущей записи
- следующая - строка с наименьшим ID что больше ID текущей записи, и type = type текущей записи
оконные функции скорее всего будут полезны для этой задачи, надо только понять как их для этого использовать
Дмитрий, нууу тогда конкретный пример 1й единственной заявки:
пример
Реальное движение:
1.08 10:00 - создана
1.08 11:00 - статус 17
1.08 12:00 - статус 18
2.08 14:00 - статус 20
2.08 15:00 - статус 21
3.08 16:00 - статус 22
Делаем запрос на даты с 2.08 по 9.08 - 7 дней
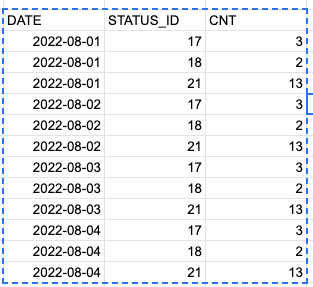
Должен получиться такой результат
2.08 | статус 18 | 1шт - тут 1 потому, что в начале дня была в этом статусе, т.е. 1 осталась еще с 1.08
2.08 | статус 20 | 1шт - тут 1 потому, что за 2.08 заявка вошла в этот статус
2.08 | статус 21 | 1шт - тут 1 потому, что за 2.08 заявка вошла в этот статус
3.08 | статус 21 | 1шт - тут 1 потому, что в начале дня была в этом статусе
3.08 | статус 22 | 1шт - тут 1 потому, что за 3.08 заявка вошла в этот статус
При этом в результате за 2.08 17 статуса быть не должно, потому, что заявка в течении 2.08 никогда в этом статусе не была, в отличие от 18 статуса
Дмитрий, а вот теперь понял (просто обычно id - это id самой строки, а если в строке есть id связанной записи, то обычно это <сущность>_id, поэтому я и не понял)
В этом случае получается, что мы считаем с группировками количество записей с выбранными статусами по тем заказам, которые в рамках заданного интервала этот статус получили. В этом случае в выборку попадут и записи смены статуса за пределами диапазона выборки, но с нужным статусом и которые при этом в рамках диапазона выборки хоть раз получили один из требуемых статусов.
Короче я возьму выборку с подсчетом изменений в течении часа + оказывается для другой статистики собирается информация раз в час о том, сколько заявок в каком статусе есть в конкретный момент времени. Если их просуммировать, тогда как раз получится нужная цифра - сколько было + сколько за час добавилось.
Хоть вопрос решить и не получилось в том контексте, который я изначально планировал, но реально благодарю за активную попытку помочь.
P.S.: а запрос в текущем контексте все равно не получается такой как надо, т.к. при выборке появляется много записей из предшествующего диапазона и они также группируются - т.е. если я делаю выборку за 8 месяц, то в итоге в выводе есть записи за 7й, и становится не понятно как и к какой записи из результатов 8 месяца их суммировать(((
да как это происходит то?
в темпе мы ограничиваем выборку по дате и по статусу, а в селекте снова фильтруем по тем же точно статусам И id из темпа. Т.к. условие И, то мы по сути еще раз отфильтровываем темп, а не объединяем его с чем либо еще. Т.е. это фильтрация в 2 шага. Может я ошибаюсь, но получается надо условия с датой переместить в селект, и условие ставить не и, а ИЛИ??
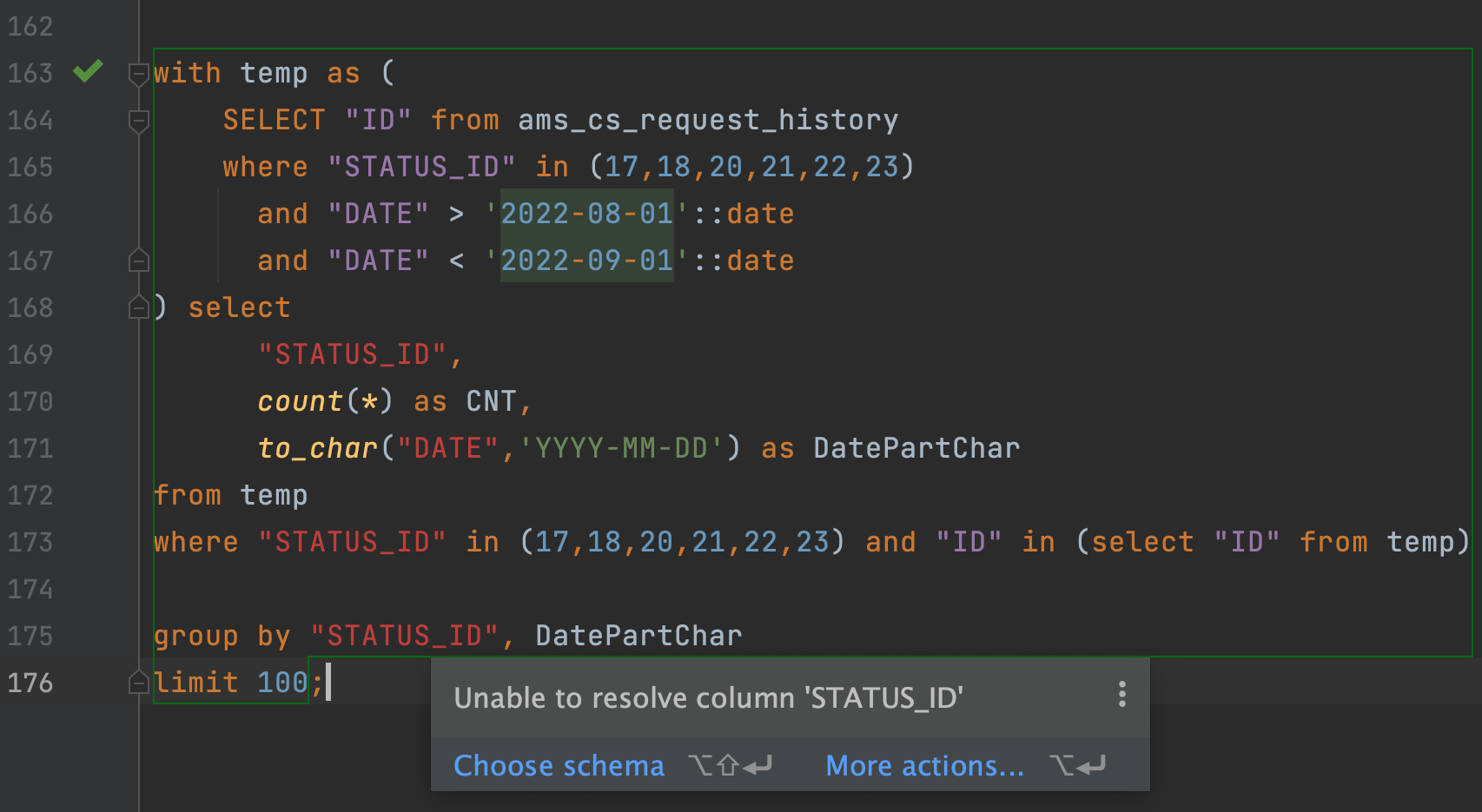
Дмитрий, 4 ну говорил же что не будет работать. Вбил все в IDE с подключением к БД, она сразу подсвечивает ошибки
а все потому, что основная выборка делается из temp (172 строка на скрине), а в него выбирается только ID, потому в 169, 173 и 175 строках подсвечивается как ошибка.
Я по сути понял задумку. Но вот вопрос а может проще разделить на 2 запроса? 1й выберет все изменения только в рамках периода, а 2й то, что было до него?
Только мне кажется тут будет куча проблем (далее мои предположения и размышления), потому, что надо будет выбрать по всем заявкам последнее изменение статуса перед отчетным периодом и отсеять те из них, которые не с одним из отчетных статусов. Вот только вроде бы это не сильно поможет, потому, что надо как то еще отфильтровать для 2-го и далее интервала те из них, которые в первом интервале поменяли статус.....
Короче та еще морока. Но так или иначе спасибо за помощь. Наверное для 2-го подсчета я воспользуюсь другими методами или просто буду считать только изменения.
Дмитрий,
1. ок, мерси
2. тут в худшем случае можно будет пожертвовать точностью, но по факту лучше в итоге иметь кол-во на конец дня вне зависимости от того стал он в этом статусе или и днем ранее был в нем же
3. я по сути хочу кол-во с группировкой по статусам, за каждый фрагмент времени (в данном случае это 1 день) на момент окончания этого фрагмента и чтобы фрагменты были в рамках общего интервала. Опять же на примере 1 недели - за пн, вт, ср и т.д.
Типа такого:
пример
По примеру кода не могу понять, это или пример, что можно temp использовать не вдаваясь в детали полей (потому, что в таком примере во втором селекте DATE и STATUS_ID не существуют, т.к. в temp выбирается только id) или я просто чего-то не понимаю(((
вот только я не могу делать по отдельному запросу на каждый день выборки, потому, что для ситуации выборки для полугодия получится слишком много запросов....
По факту наверное было бы правильнее тогда говорить что надо надо получить на каждый день сколько заявок выбранных статусов оставалось на конец дня и так на каждый день в рамках выбранного интервала.
Ну, необходимость обусловлена регламентом заказчика о порядке нумерации сервисных заявок. Просто им серверную часть давно сдали, но с нумерацией накосячили. А я на 80% фронт, на 20% бекэнд и с СУБД напрямую практически не пересекаюсь, поэтому не знаю, какие механики в posgre для этого вообще существуют...
Но в этом случае вот эта проблема все еще остается