Спасибо! Ваш совет направил в верную сторону.
В итоге я сделал следующим образом для агрегации по одному полю (как в вопросе):
SELECT DISTINCT
date,
sum(case when check = 1 then 1 else 0 end)
over (
order by date
RANGE BETWEEN
interval '14' day preceding
and
current row
) as overlap
from TABLE;
В реальной задаче мне потребовалась группировка по партиции из нескольких полей (с учетом даты Т-14), сделал так:
select distinct
COLUMN_1,
COLUMN_2,
....
COLUMN_N
date_report,
nvl(
sum(
case
when MARKER = 1 then 1
end
) over (
partition by
COLUMN_1,
COLUMN_2,
....,
COLUMN_N
date
order by
date
range between
interval '14' day preceding
and
current row
)
,0) as NEW_COLUMN
Агрегацию делаем по партиции, сортировку только по дате.
Это сработало для меня.
Спасибо за неравнодушие. Картинкой я хочу передать желаемый результат. А проблема в том, каким образом в group by или partition by поместить условие отбора, где полем группировки является дата, но при этом туда попадаются строки не только этой даты, но и несколько ранних дат.
Что-то вроде count over (partition by date where date between date and (date - 14))).
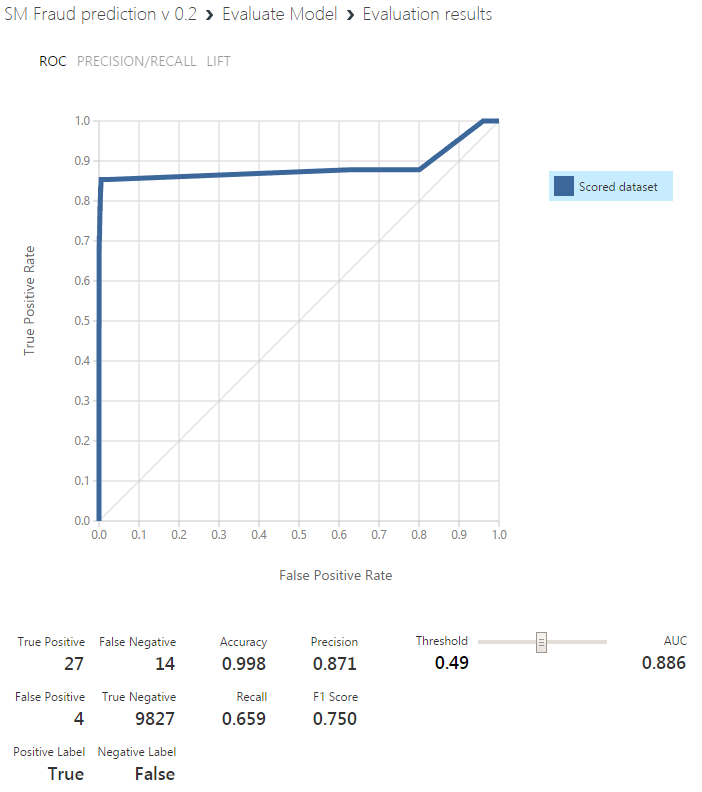
Что-то изменилось! Загнал туда одновременно 140 случаев фрода и 30000 остальных заявок. Правда True Positive только 27 значений (в идеале же 140 должно было быть?).
Если в оцененном датасете рядом с фродами вероятности стоят ближе к 100%, а рядом с другими значениями ближе к нулю, получается, все сделано верно?
В итоге я сделал следующим образом для агрегации по одному полю (как в вопросе):
В реальной задаче мне потребовалась группировка по партиции из нескольких полей (с учетом даты Т-14), сделал так:
Агрегацию делаем по партиции, сортировку только по дате.
Это сработало для меня.