Всем привет. Возникла необходимость сделать прототип модели. Модель должна предсказывать вероятность фрода(мошенничества) при выполнении заявок клиентов. В качестве данных для анализа - числа и булевы параметры (количество переназначений, является ли прочроченной и тд), которые, как я считаю, могут влиять на вероятность фрода. В azure загрузил выборку из 140 случаев подтвержденного фрода. После обучения модели и тестирования на той же выборке (соотношение 70/30) оценка модели показывает, что все значения true positive. Про тестировании модели на выборке в 30000 уже неизвестных заявок оценка модели сообщает, что все строки false positive. Прочитал много документации, перепробовал разные комбинации алгоритмов и выбираемых данных, но вменяемого результата получить не могу. Я понимаю, что данных для обучения пока очень мало и нужно хотя бы раз в 20 побольше. Но правильно ли я делаю и как правильно понять результаты? Я с такой маленькой выборкой для обучения вообще ничего не добьюсь, или я неправильно настраиваю модель в azure ml studio, и все таки что-то вменяемое можно получить хотя бы для сырого прототипа?
Алгоритм, который использовал последний раз - two classes boosted decision tree.
Буду благодарен хотя бы за комментарии от людей, которые тоже пробовали делать что -то такое. Спасибо!
Вы только примеры фрода отправили на обучение что ли, без примеров "не-фрода"? Надо и положительные, и отрицательные примеры отправлять для двухклассовой классификации. Объём данных желательно побольше, конечно, но и с небольшим объёмом корректных данных не должно быть таких результатов, как у вас.
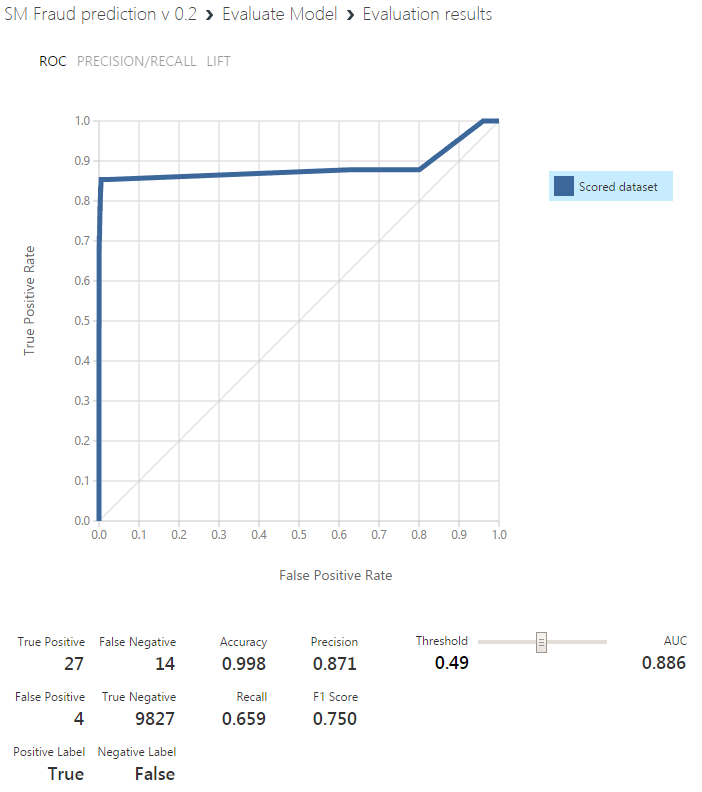
Что-то изменилось! Загнал туда одновременно 140 случаев фрода и 30000 остальных заявок. Правда True Positive только 27 значений (в идеале же 140 должно было быть?).
Если в оцененном датасете рядом с фродами вероятности стоят ближе к 100%, а рядом с другими значениями ближе к нулю, получается, все сделано верно?
Выходит, что модель уже что-то научилась обнаруживать. Процесс обнаружения вероятностный, и все 100÷ случаев фрода можно обнаружить только при большой вероятности ложной тревоги. У вас получается, что из 41 случая обнаружилось 27, а 14 - нет. При этом всего 4 ложных срабатывания на почти 10000 случаев остальных заявок. Вероятности справа относятся ко всему датасету в целом.
Для улучшения качества обнаружения можно пытаться настраивать модель, подбирать другие характеристики, увеличивать набор данных. Можно попробовать покрутить ползунок threshold справа, но, судя по ROC-кривой, больших успехов этим сейчас вы вряд ли добьётесь.
Если в остальных заявках тоже возможны случаи фрода, то стоит посмотреть на те, на которых алгоритм срабатывает, проверить их, и если это действительно фрод - перенести в правильный набор. В идеале вторая часть данных не должна содержать случаев фрода.
Данных должно быть явно больше. 140 - это ни очем.
Как вариант, можно нагенерить данные.
Берем каждую строку, и меняем один параметр. Т.о. из одной строки можно нагенерить 10-20 новых.
Но это так - метод в лоб.


 Простой
Простой
 Средний
Средний