Установить Python, PyCharm (триал версию). создать там проект, перекинуть туда этот файл:
href=
https://yadi.sk/d/A6_iVd1QY5HdRA
выставить кодировку

затем, во вкладке Database создать базу данных SQlite (или открыть файл .db другой базы данных), правой кнопкой мыши импортировать файл csv, который уже в кодировке и сделать, как на изображении ниже
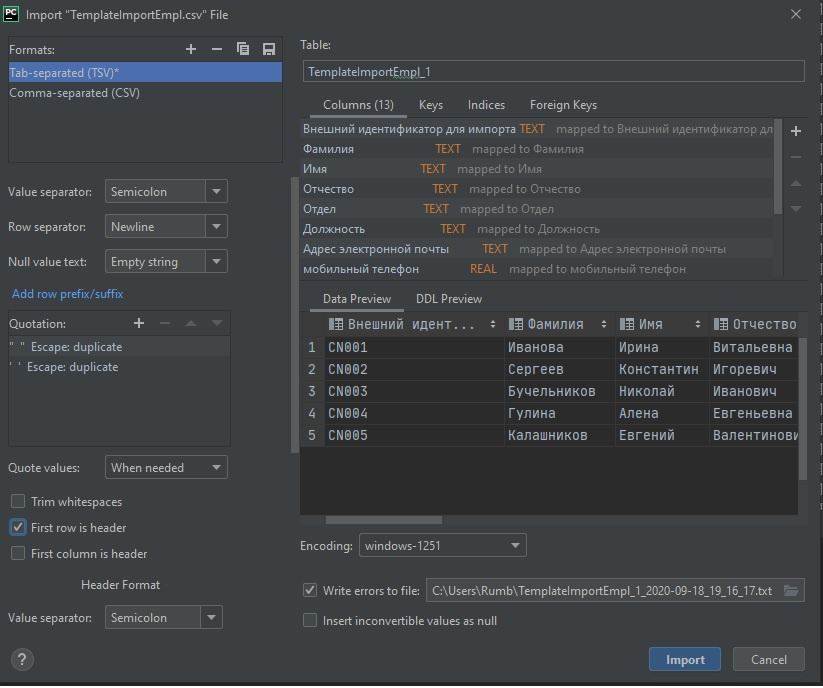
и все, заполненная база данных готова,
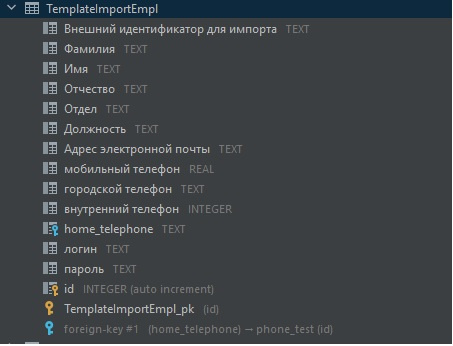
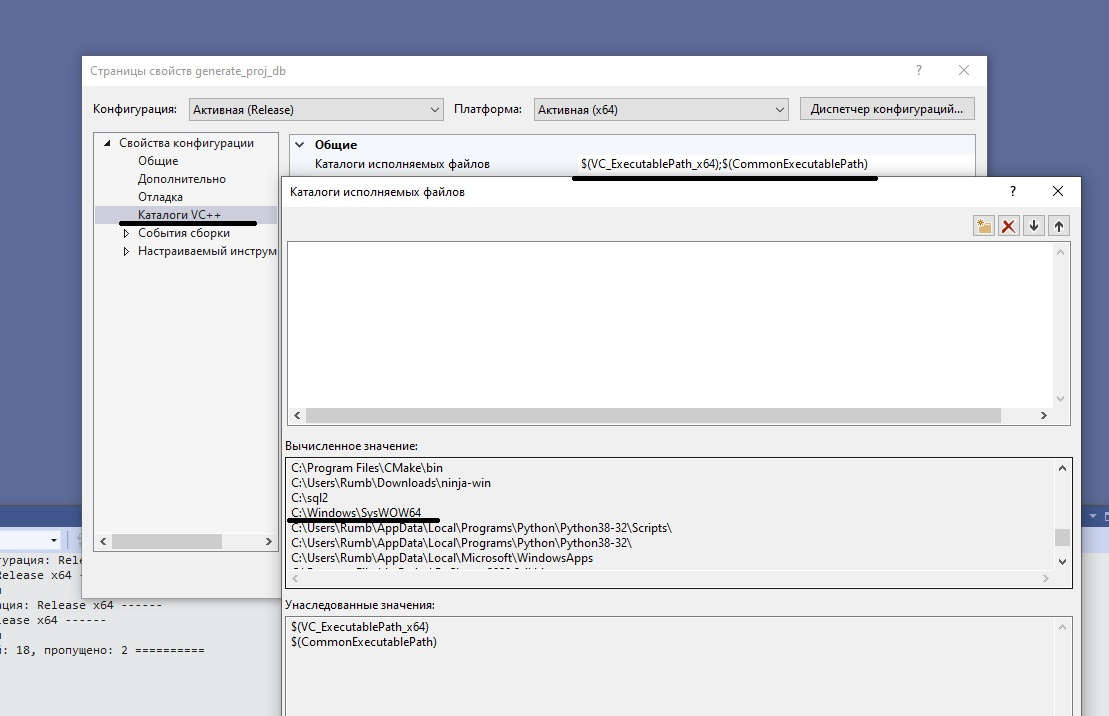
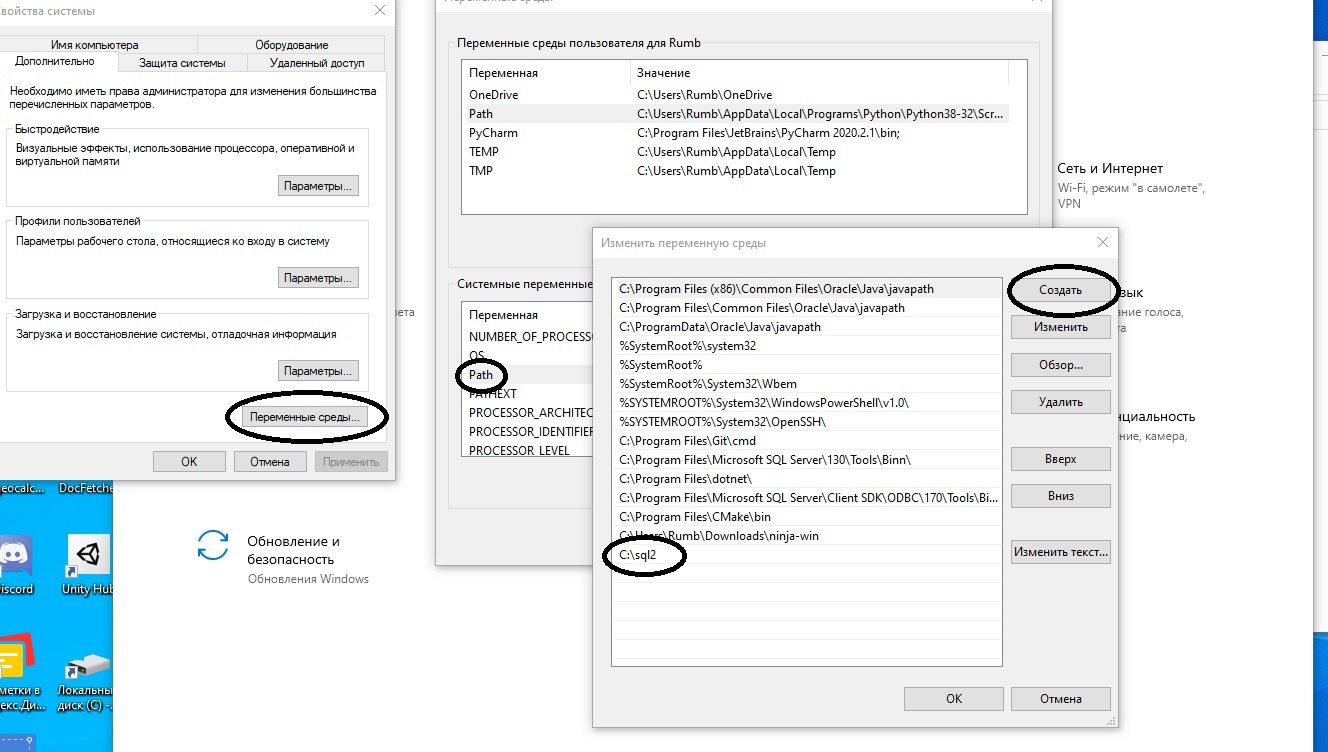
обязательно прописываем id (создаем поле в каждой таблице) с autoincrement и Primary Key (PK)
так же можно сделать связи (автоматически создаст таблицу)
пример связывания таблицы один ко многим.
1. создаем таблицу phone_test, прописываем id (autoincrement, PK)

2. переходим в первую таблицу и модифицируем колонку home_telephone
должно получиться так:
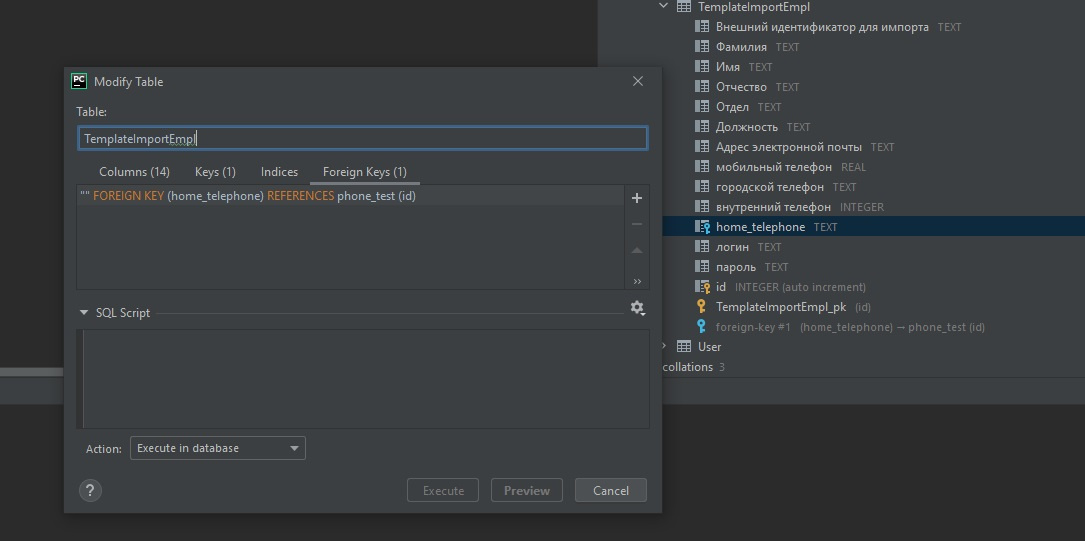
все, две таблицы связаны, во вкладке консоль прописываем тестовый запрос
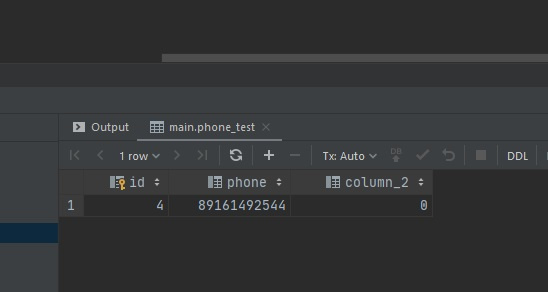
пример запроса Foreign Key Один ко многим
SELECT pt.id, pt.phone, pt.column_2 FROM TemplateImportEmpl LEFT JOIN phone_test pt on pt.id = TemplateImportEmpl.home_telephone
видим результат
 Если надо сделать из сложного XML файла таблицу CSV для любой базы данных.
Если надо сделать из сложного XML файла таблицу CSV для любой базы данных.
допустим есть такой XML файл и надо сделать таблицу CSV
<?xml version="1.0" encoding="UTF-8"?>
<services>
<strategy odn="149" name="kv" date="2020-11-18">
<post>eVoting Booth</post>
<inf>
<tag id="10" er="er1"/>
<tag id="14" er="er1"/>
<tag id="11" er="er2"/>
<tag id="12" er="er3"/>
<tag id="13" er="er4"/>
</inf>
</strategy>
<strategy odn="150" name="vk" >
<post>Library</post>
<inf>
<tag id="10" er="er1"/>
<tag id="13" er="er4"/>
</inf>
</strategy>
</services>
вот код для создания таблицы с вытаскиванием тегов и заполнением пропусков в XML
from lxml import etree
import pandas as pd
trree = etree.parse("input_file.xml")
table = trree.xpath('/services/strategy/inf/tag')
tableoutput = []
for i in table:
ig = i.xpath('./@er') #доступ к тегам и распечатка тегов, доступ к post
tableoutput+= ig
print("поля в будущей таблице: ", set(tableoutput), "сменить таблицу (экс)")
id = []
counttag = 0
minsec = []
minseccel = []
counter1musttwo = []
tagnull = []
identifie = trree.xpath('/services/strategy/inf')
for c in identifie:
counttag +=1
ct = c.xpath('./tag')
print ("количество тегов в",counttag, "inf: ", len(ct))
if (len(ct) == 0):
tagnull += "TAG = 0; inf №", counttag
print("найден inf с Количеством тегов = 0")
for c1 in ct:
ct1 = c1.xpath('./@er')
ct2 = c1.xpath('./@id')
print("распечатываем er: ", ct1)
if (ct1 == ['er1']):
id += ct2
minsec += ct1
minseccel += ct1
print("кол-во er1 в",counttag, "inf: ", minsec.count("er1"))
if (minsec.count("er1") >= 2):
counter1musttwo += "er1 > 2; inf №",counttag, "; кол-во er1", minsec.count("er1")
print("найден inf с er1 больше 2")
print(" \n ")
minsec = []
identifie = trree.xpath('/services/strategy')
for re in identifie:
reos = re.xpath('./post/text()')
print("доступ к post", reos)
#выше мы подсчитали все элементы tag
#делаем пример таблицы csv если каких то полей не хватает поле дата не постоянно
print("\n")
strategy = trree.xpath('/services/strategy')
squares = []
for rv in strategy:
noner = rv.xpath('./@date')
if (noner == []):
noner = ['not found']
squares += noner
print(squares)
postoutput = []
for re in strategy:
reos = re.xpath('./post/text()')
if (reos == []):
reos = ['not found']
postoutput+= reos
print(postoutput)
id = trree.xpath('/services/strategy/@odn')
name = trree.xpath('/services/strategy/@name')
df = pd.DataFrame({
"Id": id,
"Name": name,
"Data": squares,
"Post": postoutput
})
df.to_csv("out.csv", sep="|", index=None)
#файл готов
в консоле: