Я спроектировал такую систему для получения аудио записей из текста. Сейчас обучаю несколько моделей - каждый в своем репозитории.
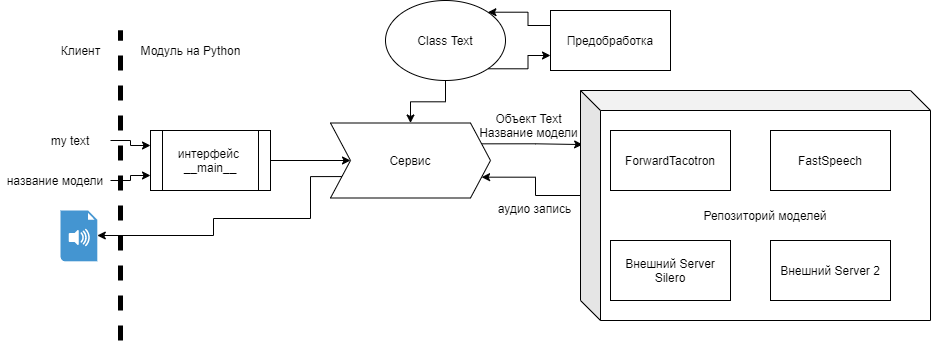
Не понимаю как мне теперь все эти модели объединить в едином репозитории и как работать с ними?
Ничего подобного раньше не делал... И на питоне редко пишу, подскажите, пожалуйста, как такое организовать?
Может кто-нибудь знает пример кода подключения этого дела (в кубе Репозиторий моделей)?
Вот пример 1 репозитория из куба Репозиторий моделей
репозитория FastSpeech2.
Когда пользователь отправит запрос mymodule.main('fastspeech', 'скажи сыр'), надо чтобы сервис подключил модули репозитория FastSpeech2 и вызвал у него модуль inference.py для генерации аудио.

