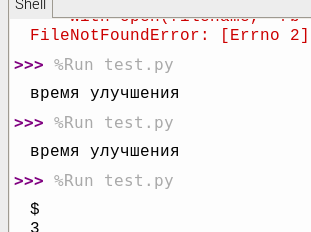
pytesseract.image_to_string('time.jpg', lang='rus', config='--oem 3 --psm 13')

 Средний
Простой
Сложный
Средний
Средний
Простой
Сложный
Средний