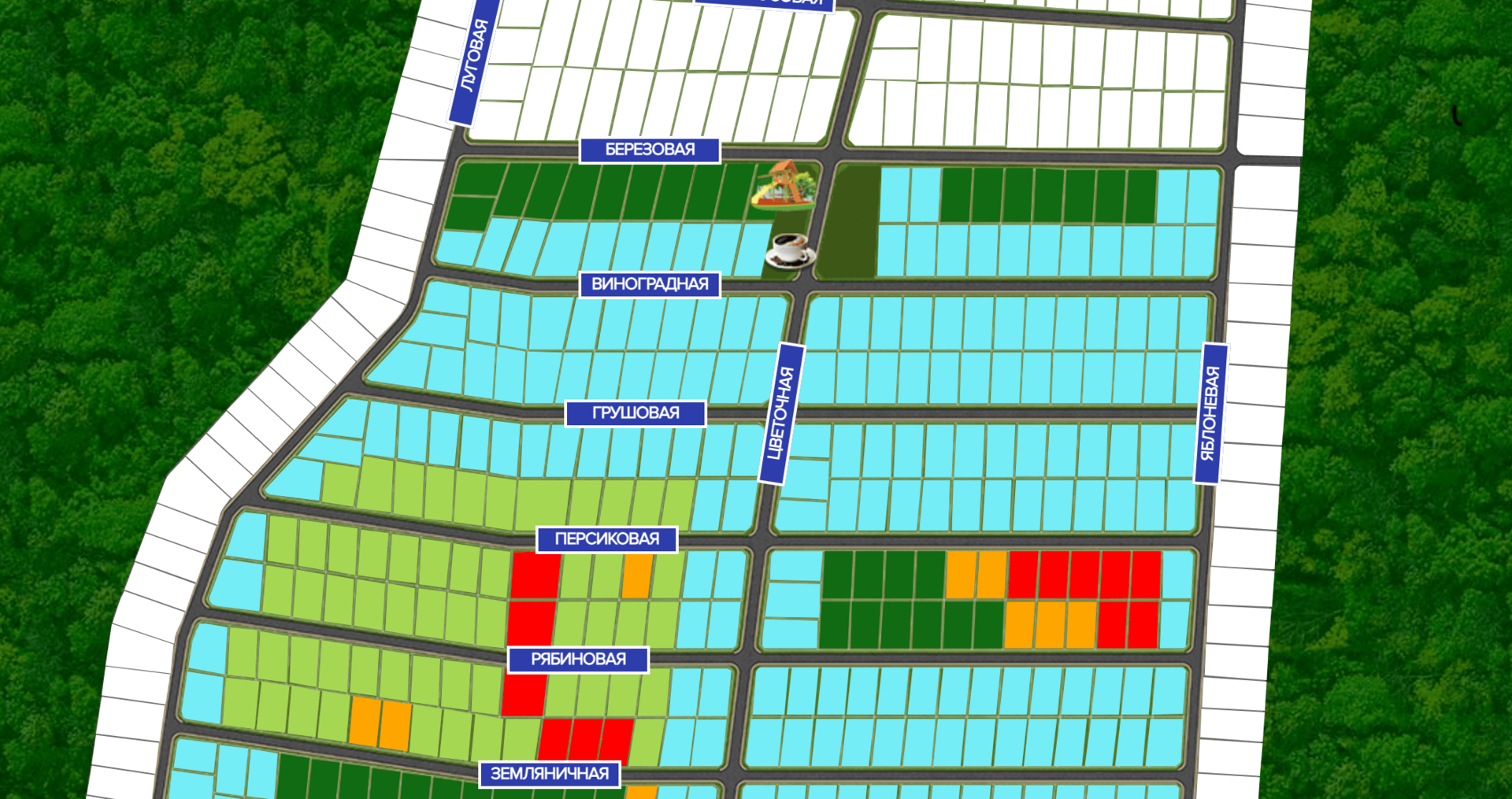
Здравствуйте. Есть вот такой генплан выше, созданный в формате SVG - у него есть теги G + полигоны, которые через fill перекрашиваем по статусам. Вся информация хранится в файле php. Формат каждого из участка примерно такой:
<g id="_1" class="someclass" data-kadastr="номер_кадастра" data-sotki="кол_во_соток_земли">
<polygon class="status_green" points="цифры_обозначающие_расположение_участка">
Нас интересует сейчас - подстановка уже не inline из php файла, а уже из базы MySQL именно
класса polygon для каждого из 700 участков. В примере - .status_green, может быть .status_red и прочие. Именно этот класс и отвечает за цвет участка. И этот класс для каждого из 700 участков хочется получать из бд правильно, так скажем используя best practices, если можно так выразиться.
data-kadastr & data-sotki могут оставаться в инлайн формате в php, без базы данных.
Хочу посоветоваться по поводу подхода -
появилась необходимость после онлайн бронирования участка иметь возможность на лету изменить цвет участка.
Не проданный по умолчанию - зеленый, например. Проданный - красный.
Моя теория:
у нас 700 участков, создаю MySQL базу, в которой в соответствии с ID каждого участка в базе есть строки - ID и STATUS (или же color, не важно). В ID храним цифру 1,2,3,4,5..... в соответствии с номером, в STATUS - храним просто код цвета (код класса) status_red / status_green / status_lightblue. Предположим, что я вручную заполнил данную базу и в ней все актуально хранится.
Вопрос 1 - верно ли я представляю архитектуру БД для данной задачи? Или есть другие более правильные варианты?
Вопрос 2 - какой подход использовать для получения всех этих данных и построения генплана из базы данных, что бы не было дикой нагрузки? Что бы скорость загрузки была не дико медленная. Тк в моей голове это 700 запросов к базе данных для каждого участка. (UPD - для всех участков генплана, 1 запрос на 1 участок, не правильно выразился)


