
df = pandas.DataFrame()
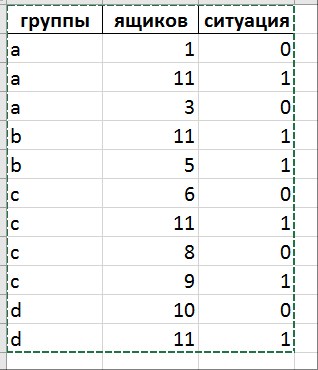
df['группы'] = ['a','a','a','b','b','c','c','c','c','d','d']
df['ящиков'] = [1,11,3,11,5,6,11,8,9,10,11]
df['ситуация'] = [0,1,0,1,1,0,1,0,1,0,1]
dfSELECT
"группы",
COUNT(DISTINCT CASE WHEN "ситуация" = 1 THEN "ящиков" END) AS "уникальных_ящиков_при_ситуации_1",
SUM(CASE WHEN "ситуация" = 0 THEN "ящиков" END) AS "сумма_ящиков_при_ситуации_0",
..
..
GROUP BY "группы"
import pandas
df = pandas.DataFrame()
df['группы'] = ['a', 'a', 'a', 'b', 'b', 'c', 'c', 'c', 'c', 'd', 'd']
df['ящиков'] = [1, 11, 3, 11, 5, 6, 11, 8, 9, 10, 11]
df['ситуация'] = [0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1]
print(df[df['ситуация'] == 1].groupby('группы').count())
print(df[df['ситуация'] == 0].groupby('группы').sum()) Средний
Простой
Средний
Простой