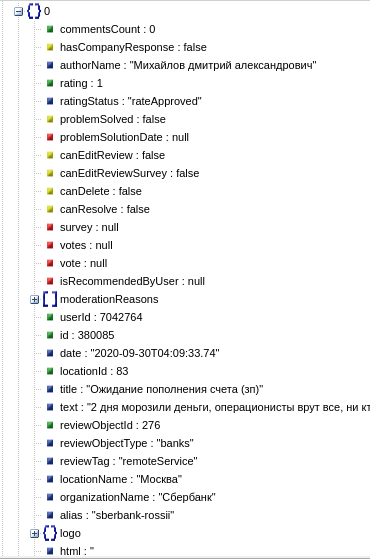
Ребят, файл удалился, делаю на скорую руку, уже мозги кипят, помогите разобраться.
import requests
from bs4 import BeautifulSoup
HEADERS = {
'User-Agent': 'тут юзер аджент',
'Accept':'тут ассепт'
}
HOST = 'https://www.sravni.ru/bank/sberbank-rossii/'
URL = HOST + 'otzyvy/'
def get_html(url, params = ''):
r = requests.get(url,headers =HEADERS, params=params)
return r
def get_content(html):
soup = BeautifulSoup(html, 'html.parser')
items = soup.find_all('div', class_ ='_227VT')
otzivi = []
for item in items:
otzivi.append(
{
'name': item.find('div', class_='_1tvOC r2Q86').find('div', class_='_3qkdy _7QkVd').find('div', class_='_3bNvn').find('div', class_='_1ubS9 yHpsJ').find('div', class_='_1ubS9 yHpsJ').find('span').get_text()
}
)
return otzivi
html = get_html(URL)
print(get_content(html.text))
ОШИБКА:
Traceback (most recent call last):
File "C:\Users\Я\AppData\Local\Programs\Python\Python38-32\d.py", line 40, in
print(get_content(html.text))
File "C:\Users\Я\AppData\Local\Programs\Python\Python38-32\d.py", line 29, in get_content
'name': item.find('div', class_='_1tvOC r2Q86').find('div', class_='_3qkdy _7QkVd').find('div', class_='_3bNvn').find('div', class_='_1ubS9 yHpsJ').find('div', class_='_1ubS9 yHpsJ').find('span').get_text()
AttributeError: 'NoneType' object has no attribute 'find'