public class readAllLinks {
Названия классов должны начинаться с заглавной буквы. Прочитайте про name convention
Что касается вашего кода, то есть много нюансов.
мне нужно взять карточки товара сайта (цена, фотографии,описание и тд) чтобы забрать все карточки товара я должен подключиться к сайту (я сделал)
Вы просто открыли главную страницу сайта и выбрали ВСЕ ссылки (тег а).
Elements links = doc.select("a");
Теперь вопрос как мне переходить по всем ссылкам сайта и забирать только информацию товара?
Я бы сделал следующим образом. Вместо того, чтобы собирать все ссылки, я бы собрал ссылки на разделы (категории).
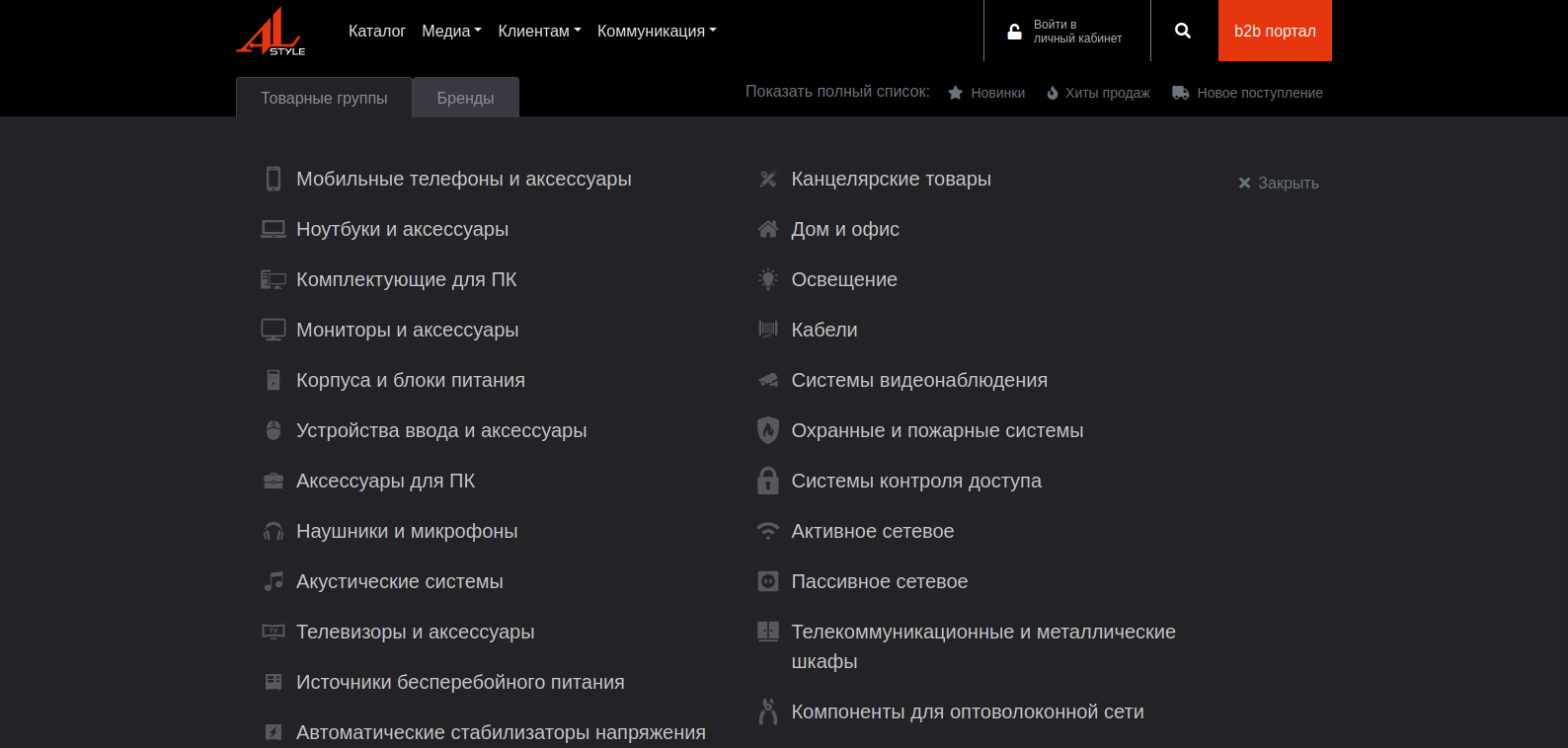
Вот, селектор
#categories .sub-menu-item .sub-menu-link
Далее собираете их в какой-нибудь List
Далее итерируете по этому списку и переходите по ссылке, также как и здесь
doc = Jsoup.connect(url).userAgent("Mozilla").get();
вместо url будет ссылка из листа спарсенная из меню (картинка выше)
Страница каталога товаров имеет пагинацию.
Например,
https://al-style.kz/catalog/mobilnye_telefony/
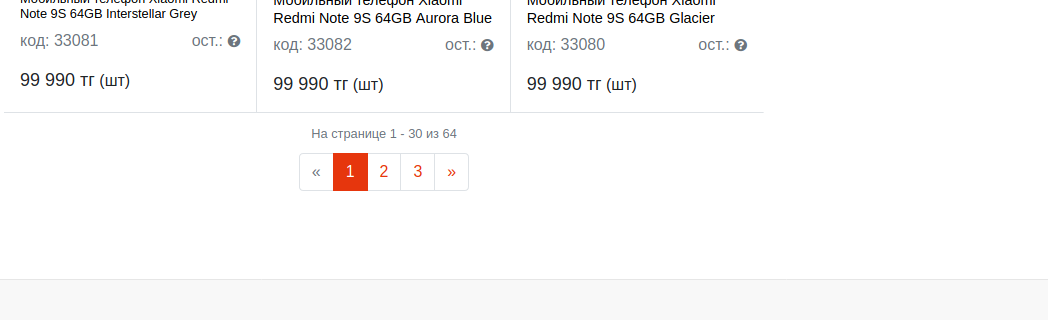
Смотрим, как работает пагинация
https://al-style.kz/catalog/mobilnye_telefony/
https://al-style.kz/catalog/mobilnye_telefony/?PAGEN_1=2
?PAGEN_1={pageNum}
По факту к урл добавляется query param, который инкрементируется, а значит после того, как мы перешли на страницу категории, мы для каждой категории добавляем этот параметр и инкрементируем его значение до тех пор, пока страницы не закончатся. В зависимости от сайта можно по-разному проверять есть ли страница или нет.
Например, проверить просматривется ли или существует ли тот или иной блок.
Далее на каждой странице находим блоки (карточки товара).
Вот, селектор:
.elements .element
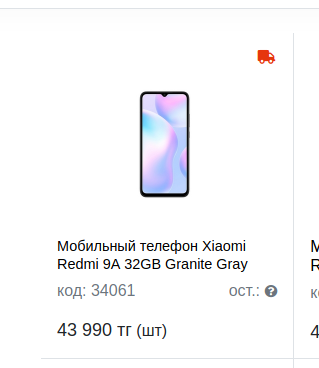
Находим селектор ссылки и сохраняем тоже в отдельный List
.elements .element .link
После того, как постранично прошлись по категории и собрали список всех ссылок карточек товара итерируем по этому списку и также открываем эти ссылки.
Т.е. страницу самого товара - например,
https://al-style.kz/catalog/mobilnye_telefony/mobi...
Ну а дальше остается собрать данные при помощи в селекторов, сохранить в pojo (например, Product ) и экспортировать куда-нибудь.
Для экспорта в xlsx можно использовать Apache POI


 Средний
Средний
 Сложный
Сложный


