Други!
Помогите, пожалуйста.
Суть: существует некая БД, в которой существует таблица без первичного ключа и нумерации строк.
В данной таблице завелись дубликаты строк.
Необходимо написать sql-запрос, который бы удалял дубликаты.
Работы проходят в Postgresql, версия 11.9.
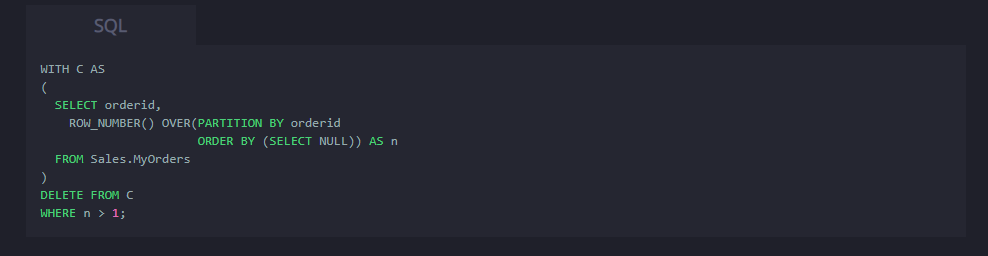
Порыскав в интернете, наткнулась на данную статью:
https://vc.ru/dev/134435-sposoby-udaleniya-dublika...
Т.к. в нашем случае в таблице отсутствует первичный ключ, был выбран второй вариант, а именно через оконную функцию ROW_number().
Вот пример моего кода:
WITH D AS
(
select s.*,
row_number () over (Partition by s.*
) as numbering
from sales s
)
delete FROM D
WHERE numbering > 1;
После чего Postgre выдаёт такую ошибку: "ERROR: ОШИБКА: отношение "d" не существует
LINE 8: delete FROM D"
Хотя если попробовать селектнуть данное обобщенное выражение то ошибок нет.
WITH D AS
(
select s.*,
row_number () over (Partition by s.*
) as numbering
from sales s
)
select * from D
Подскажите, пожалуйста, с чем связанна данная ошибка?
Я в этом деле ещё совсем новичок.
Всем заранее спасибо:)



 Средний
Средний
 Простой
Простой