
from PIL import Image
import pytesseract
import cv2
import os
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract.exe'
base_dir = os.path.dirname(os.path.abspath(__file__))
image = base_dir + r'\tmp\test.PNG'
d = Image.open(image)
preprocess = "thresh"
# загрузить образ и преобразовать его в оттенки серого
image = cv2.imread(image)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# проверьте, следует ли применять пороговое значение для предварительной обработки изображения
if preprocess == "thresh":
gray = cv2.threshold(gray, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# если нужно медианное размытие, чтобы удалить шум
elif preprocess == "blur":
gray = cv2.medianBlur(gray, 3)
# сохраним временную картинку в оттенках серого, чтобы можно было применить к ней OCR
filename_dir = base_dir +"\gray\{}.png".format(os.getpid())
cv2.imwrite(filename_dir, gray)
# загрузка изображения в виде объекта image Pillow, применение OCR, а затем удаление временного файла
text = pytesseract.image_to_string(Image.open(filename_dir))
print(text)
os.remove(filename_dir)
# показать выходные изображения
cv2.imshow("Image", image)
cv2.imshow("Output", gray)





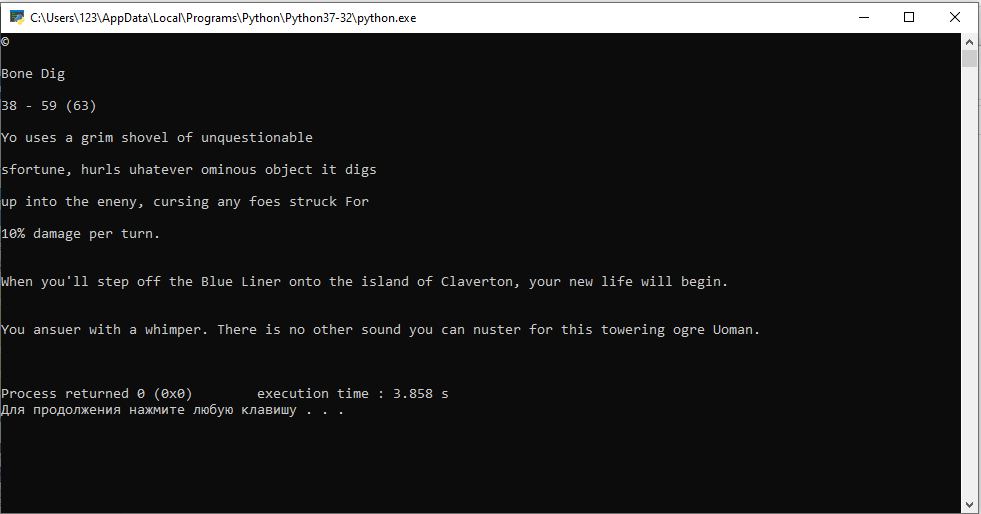
fright, tine to put the old girl to work.
When you'll step off the Blue Liner onto the island of Cloverton, your new life will begin.
O Bone Dig
23 - 59 (63)
ME ero rpart
toc mary
v fits te arg Saahe any Mn fof
Poth
import cv2
import pytesseract
def text(img, size, chan):
pytesseract.pytesseract.tesseract_cmd = r'Tesseract-OCR\tesseract.exe'
scale_percent = int(size)# Процент от изначального размера
image = cv2.imread(img)
width = int(image.shape[1] * scale_percent / 100)
height = int(image.shape[0] * scale_percent / 100)
dim = (width, height)
resized = cv2.resize(image, dim, interpolation = cv2.INTER_AREA)
gray = cv2.cvtColor(resized, cv2.COLOR_BGR2GRAY) #
ret, threshold_image = cv2.threshold(gray, chan, 150, 1, cv2.THRESH_BINARY)
text = pytesseract.image_to_string(threshold_image, config='--psm 11')
# cv2.imshow("123", threshold_image)
# cv2.waitKey(0)
return text
text1 = text("1.png", 350, 150)
print(text1,"\n\n")
text2 = text("2.png", 350, 30)
print(text2,"\n\n")
text3 = text("3.png", 350, 160)
print(text3,"\n\n")
 Сложный
Средний
Простой
Простой
Сложный
Средний
Простой
Простой