Ввиду рабочей необходимости часто требуется обращаться к кредитным рейтингам, что весьма утомительно и продолжительно по времени из-за слабого интернет-соединения и маломощного компьютера. В связи с этим решил собрать таблицу в Google Docs вместе с необходимыми данными, всегда доступными для использования.
С сайта Fitch Ratings мне необходимо вытащить следуюший рейтинг:

Ссылка на страничку:
Fitch Ratings
Используя ассистент Google Docs, желаемого результата не достиг:

Попытался также использовать Full XPath в запросе, ничего не вышло:

Пытался иначе, начитавшись материалов в сети, также не вышло:

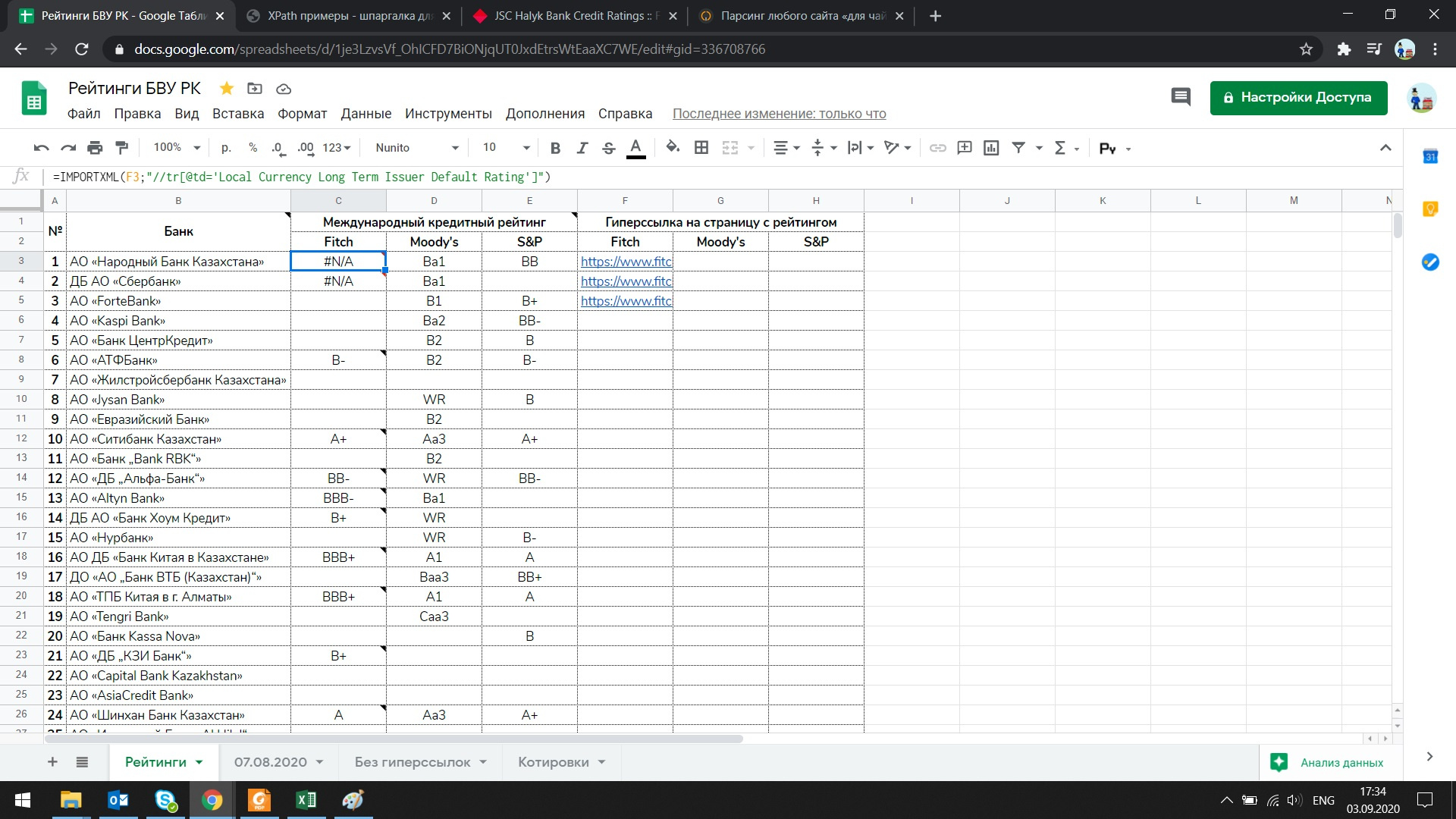
Подскажите, пожалуйста, где именно и в чем я допустил ошибку при составлении запроса?
P. S. Также, если не сложно, можете подсказать, возможно ли вытащить данные о рейтингах с сайтов, где необходима авторизация для доступа к данным (сайты рейтинговых агентств S&P и Moody's Investors Service)?
Спасибо за внимание!



 Простой
Простой
