Всем привет.
Есть следующая задача (практикуюсь): спарсить название вакансии и ее ссылку с сайта.
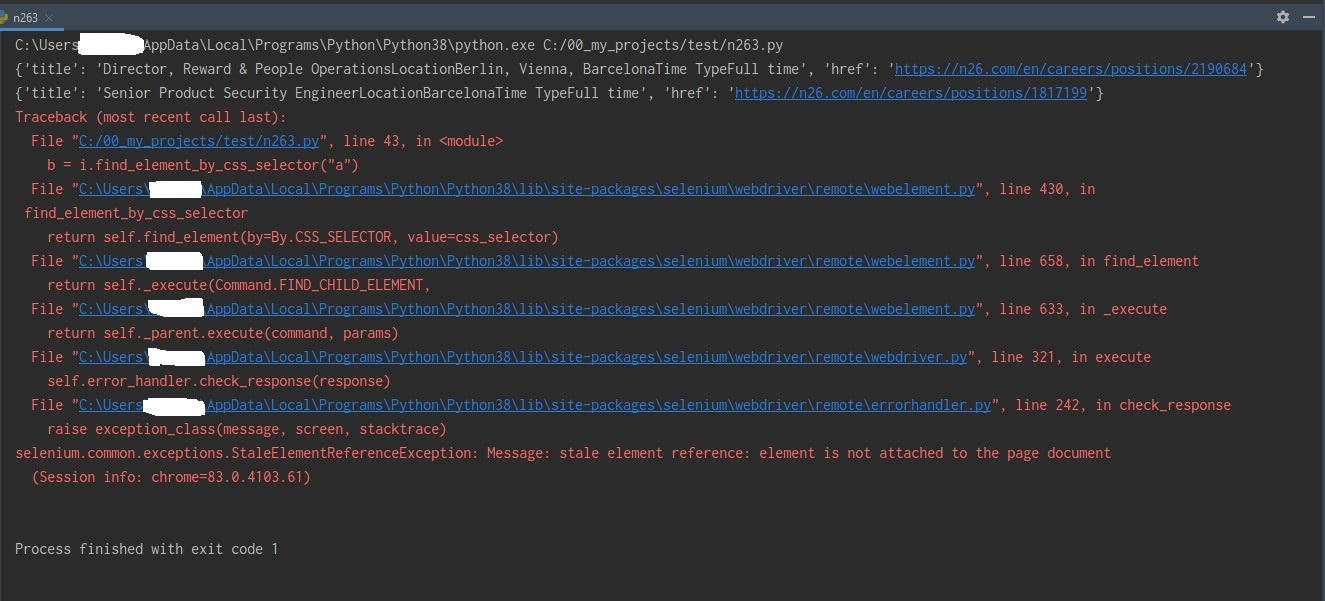
Первоначальная ссылка на сайт показывает вакансии в одном городе. После успешного парсинга вакансий из этого города нажимаю кнопку другого города для парсинга следующей порции вакансий. И на этом этапе ничего не происходит - появляется ошибка:
selenium.common.exceptions.StaleElementReferenceException: Message: stale element reference: element is not attached to the page document
По логике я хотел переходить от одного города к другому и парсить вакансии. Далее я все добавлю в список и загружу в бд.
Вторая проблема:
При парсинге вакансии название тащит за собой тексты дочерних элементов. Как можно это запретить?
Результат сейчас:
'title': 'Director, Reward & People OperationsLocationBerlin, Vienna, BarcelonaTime TypeFull time'
Желаемый результат:
'title': 'Director, Reward & People Operations'
Третья проблема:
Использование абсолютного пути в xpath. Пока не трогаю - потом исправлю.
Понятно что код можно сделать намного эффективнее, но у меня сейчас не стоит такая задача. Хотелось бы получить сначала работающий скрипт. Но полезным советам по организации данного кода буду благодарен.
Спасибо.
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from datetime import date
import sqlite3
chromedriver = 'C:\\chromedriver.exe'
driver = webdriver.Chrome(chromedriver)
driver.get('https://n26.com/en/careers/locations/57663')
while True:
try:
WebDriverWait(driver, 20).until(
EC.element_to_be_clickable((By.XPATH, '/html/body/div[2]/div/div[2]/div/div[3]/button[1]'))).click()
except TimeoutException:
break
jobs = []
section = driver.find_elements_by_xpath("//ul[@class='ah aj al an ap aq jp kd ke kf kg']//li")
for i in section:
a = i.find_element_by_css_selector("a")
job = {
'title': a.get_property('text'),
'href': a.get_attribute("href")
}
print(job)
jobs.append(job)
driver.execute_script("window.scrollTo(0, 300)")
driver.find_element_by_xpath("//a[@href='/en/careers/locations/49747']").click()
section2 = driver.find_elements_by_xpath("//ul[@class='ah aj al an ap aq jp kd ke kf kg']//li")
for i in section:
b = i.find_element_by_css_selector("a")
job2 = {
'title': b.get_property('text'),
'href': b.get_attribute("href")
}
print(job2)
jobs.append(job2)
# print(jobs)