пытаюсь написать автоматический вход на сайт с дальнейшим парсингом результатов.
Авторизационная форма кроме логина и пароля пересылает
hidden __csrf_token.
Вопрос 1
Правильно ли что сначала нужно этот вебсайт считать GET запросом, потом вытащить из HTML текста
__csrf_token и его вместе с логином и паролем отправить следующим запросом для входа на сайт?
если неправильно, то как сделать?
Вопрос 2
Предполагая, что моя логика в Вопросе 1 правильная, пытаюсь нижеуказанным кодом считать сайт.
import requests
from bs4 import BeautifulSoup
s = requests.Session()
_url_00 = "https://www.filter-technik.de/account"
x_00 = s.get(_url_00)
with open("_ELSAESSER_000.html", "w", encoding='utf-8') as f:
f.write(x_00.text)
soup_00 = BeautifulSoup(x_00.text, "html.parser")
_match = soup_00.find("__csrf_token")
print(_match)
input()
как оказывается, при считывании таким способом,
__csrf_token в тексте файла не сохраняется

хотя при сохранении в мозилле файла типа Ctrl+S, этот токен там виден
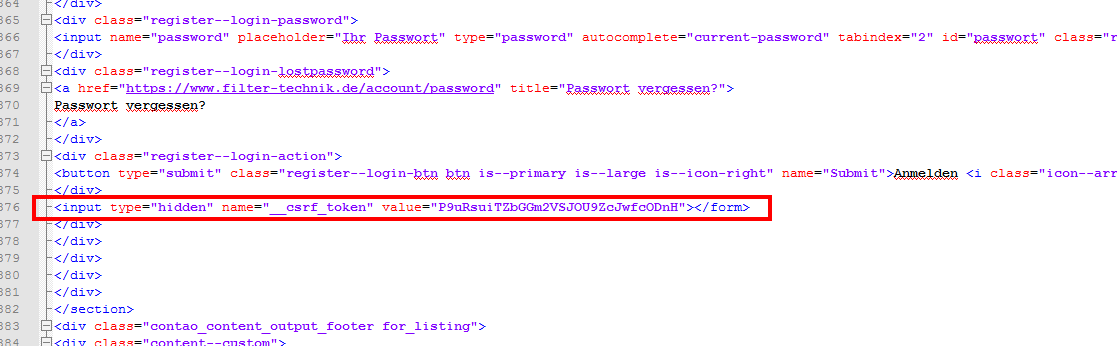
Как правильно считать файл вместе с
hidden __csrf_token??

 Сложный
Сложный
 Простой
Простой

