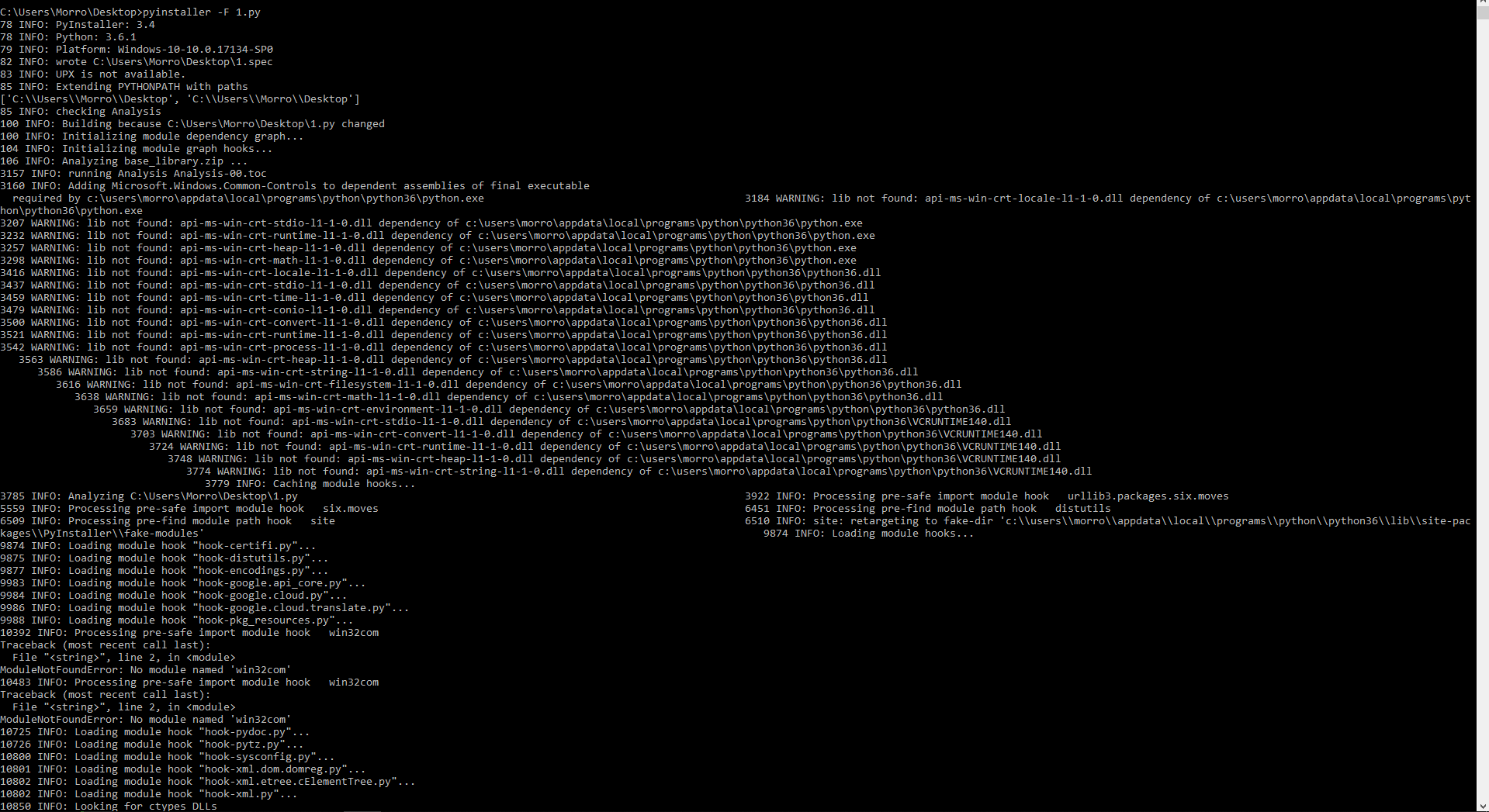
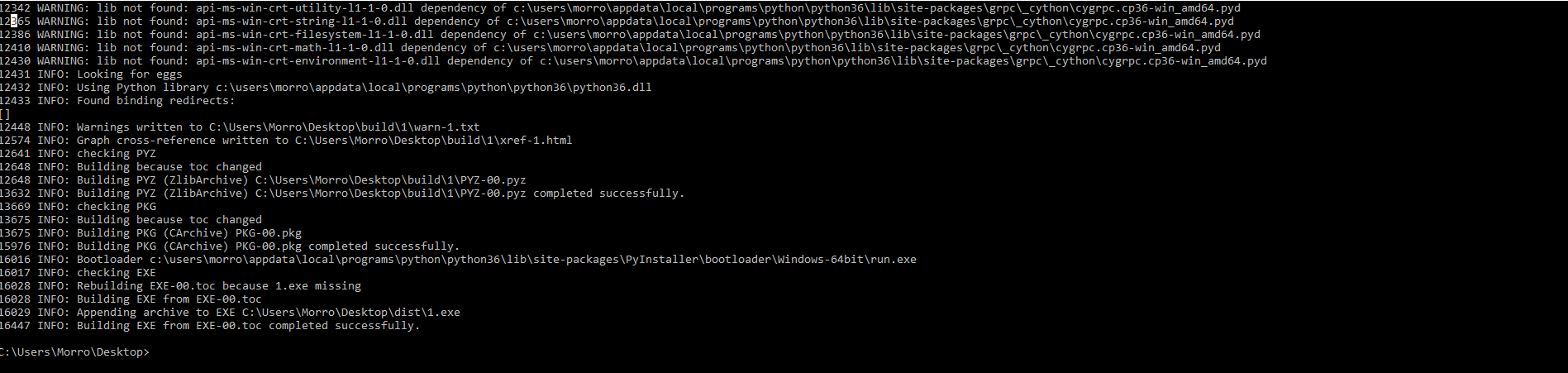
Переделываю python файл в exe командой pyinstaller -F 1.py. Во время работы выдает:
https://gist.github.com/DrMorro228Pek/3c0e8c18a3f8...
Вот код программы(из питон файла он работает):
# -*- coding: utf-8 -*-
import webbrowser, requests
from bs4 import BeautifulSoup as bs
import io
import os
from google.cloud import translate
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]=r"C:\Users\Morro\Desktop\apikey.json"
target="ru"
maybe=[]
be=[]
# Imports the Google Cloud client library
from google.cloud import vision
from google.cloud.vision import types
# Instantiates a client
client = vision.ImageAnnotatorClient()
translate_client = translate.Client()
# The name of the image file to annotate
file_name = os.path.join(
os.path.dirname(__file__),
input("Введите относительный путь к файлу. (Относительный путь — это путь, который указывает на расположение файла относительно корневой папки. Допустим Рецептовик находится там же, где и картинка, тогда достаточно будет указать имя и расширение картинке в таком формате: image.jpg): "))
# Loads the image into memory
with io.open(file_name, 'rb') as image_file:
content = image_file.read()
image = types.Image(content=content)
# Performs label detection on the image file
response = client.label_detection(image=image)
labels = response.label_annotations
for text in labels:
translation = translate_client.translate(
text.description,
target_language=target)
if translation['translatedText'] != "блюдо" and translation['translatedText'] != "питание" and translation['translatedText'] != "варка"and translation['translatedText'] != "Ингредиент":
maybe.append(translation['translatedText'])
base_url="https://ru.wikipedia.org/wiki/Категория:Блюда_по_алфавиту"
headers = {'accept': '*/*','user-agent': 'Mozilla/5.0(X11;Linux x86_64...)Geco/20100101 Firefox/60.0'}
def hh_parse(base_url, headers):
for food in maybe:
base_url="http://tvoirecepty.ru/search/apachesolr_search/" + food
session = requests.session()
request = session.get(base_url, headers=headers)
if request.status_code == 200:
soup = bs(request.content, 'html.parser')
h2s = soup.find_all('h2')
for h2 in h2s:
if str(h2).find("ничего") != -1:
break
else:
be.append(food)
break
else:
print("Fail, but Serega is nice")
hh_parse(base_url, headers)
for food in be:
food = food.replace(' ', '%20')
recipe_url = 'http://tvoirecepty.ru/search/apachesolr_search/'+ food
webbrowser.open(recipe_url, new=2)
print("\nСкорее всего, на картинке изображено:")
count=0
for i in be:
count+=1
print(str(count)+")" + i)
input("\nВведите номер, который, по вашему мнению, больше всего подходит к изображению. Это поможет улучшить работу программы: ")
input("\nСпасибо!")
Когда запускаю получившийся exe, выдает:
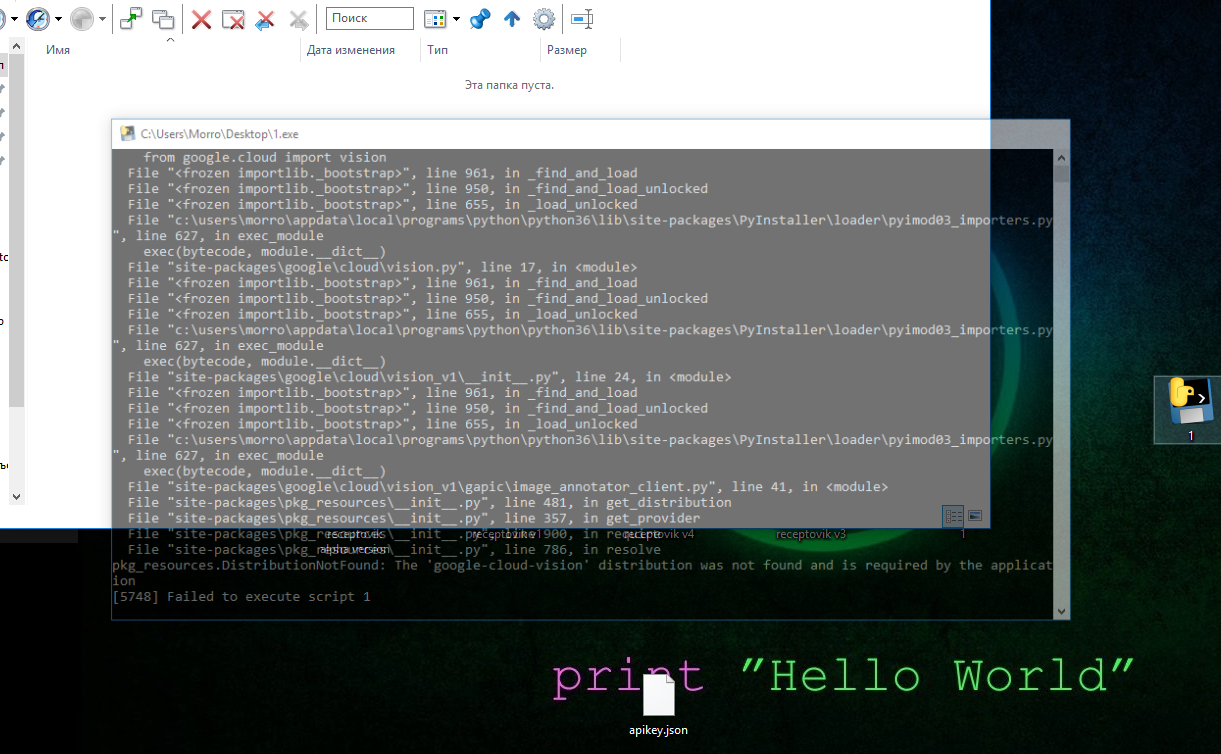
Я новичок, помогите пожалуйста. Заранее спасибо.