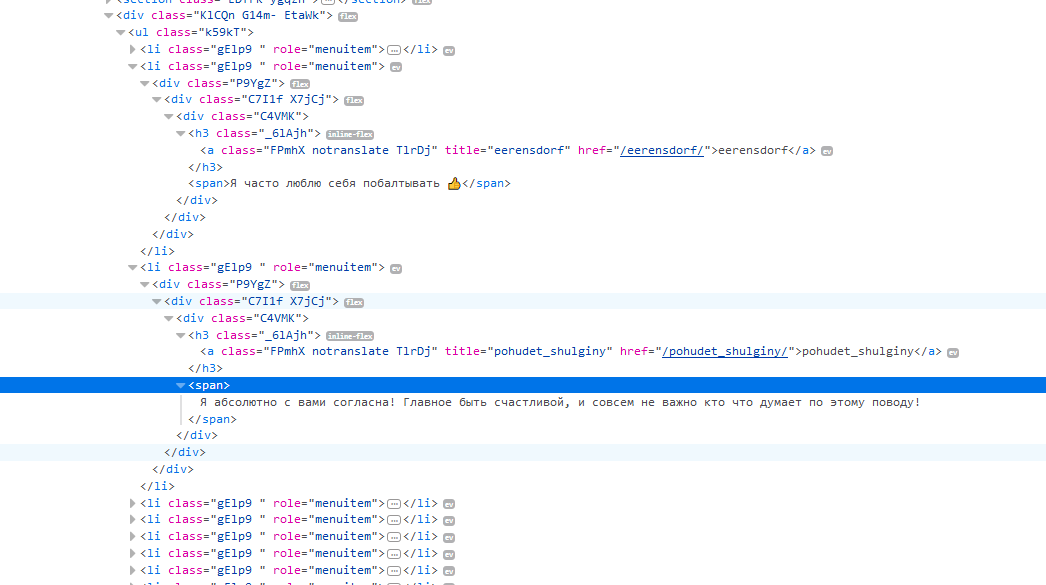
Подскажите плиз как в print вывести все значения
class="FPmhX notranslate TlrDj" title=" вот это надо "
и текст span
то есть просто принтов вывести по очереди все значения title \n + текст span
Я не понимаю как сделать for to do, while или как тут положено :(
#http://qaru.site/questions/16889278/beautiful-soup-find-is-returning-none
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import requests, re, json
import codecs
import sys
import logging
logging.basicConfig(format = '%(asctime)s : %(levelname)s : %(message)s', level = logging.DEBUG)
# -*- coding: utf-8 -*-
def main():
options = Options()
options.add_argument("--headless")
driver = webdriver.Chrome(
options=options, executable_path="C:\Python37\Laba\chromedriver.exe"
)
try:
driver.get("https://www.instagram.com/p/BvWM5KOnaQl/")
soup = BeautifulSoup(driver.page_source, "lxml")
class_k59kT=soup.find("ul", {"class": "k59kT"})
print(str(class_k59kT.find('h3').a.get('title')))
finally:
driver.quit()
if __name__ == "__main__":
main()

