from urllib.request import urlopen
html = urlopen("https://wallpaperscraft.ru")
print(html.read())
"""
output:
b'\x1f\x8b\x08\x00\x00\x00\x00\x00\x00\x03\xed]{\x8f\x1b\xc7\x91\xff_\x9fb\x8e\x81#\t\x10\x97\xef\xc7J\xbb\x1b8~\xc09\xe4.\x06\
и так далее...
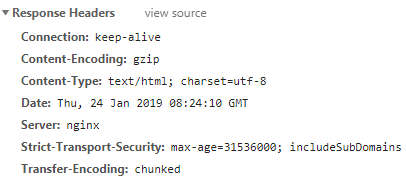
""">>> html.info()
<http.client.HTTPMessage object at 0x10aef1518>
>>> html.info().items()>>> data = html.read()
>>> import gzip
>>> gzip.decompress(data)>>> import requests
>>> response = requests.get("https://wallpaperscraft.ru")
>>> response.content