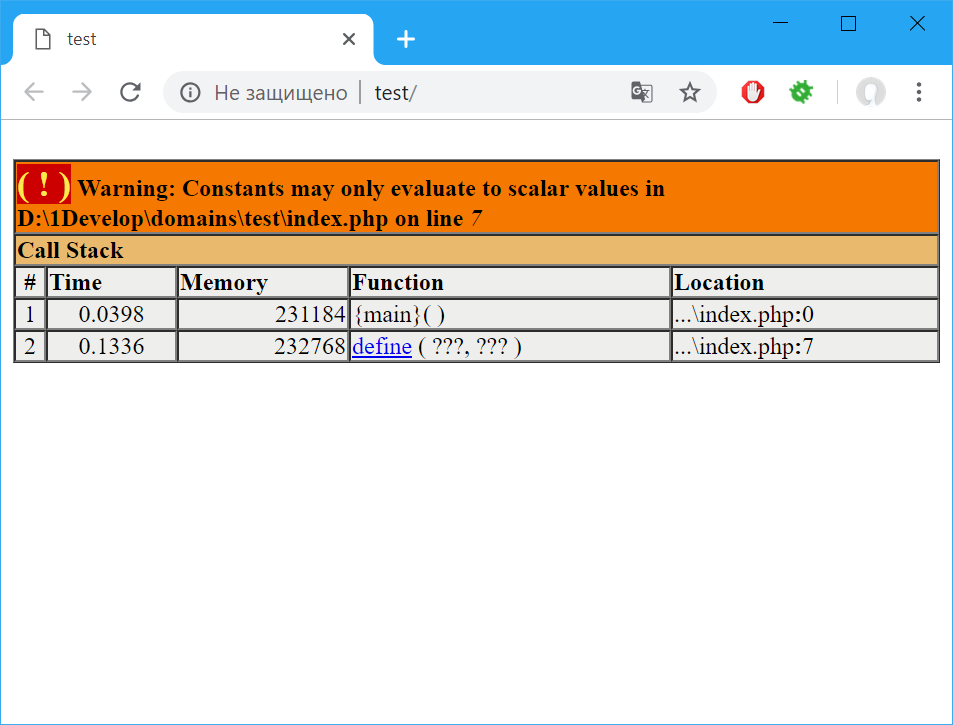
Здравствуйте. Мне нужно распарсить книгу и взять только контент - главы и их текст, оставив благодарности, оглавление, сноски и тд. Проблема в том, что в одном файле две книги. Я написал вот такой код:
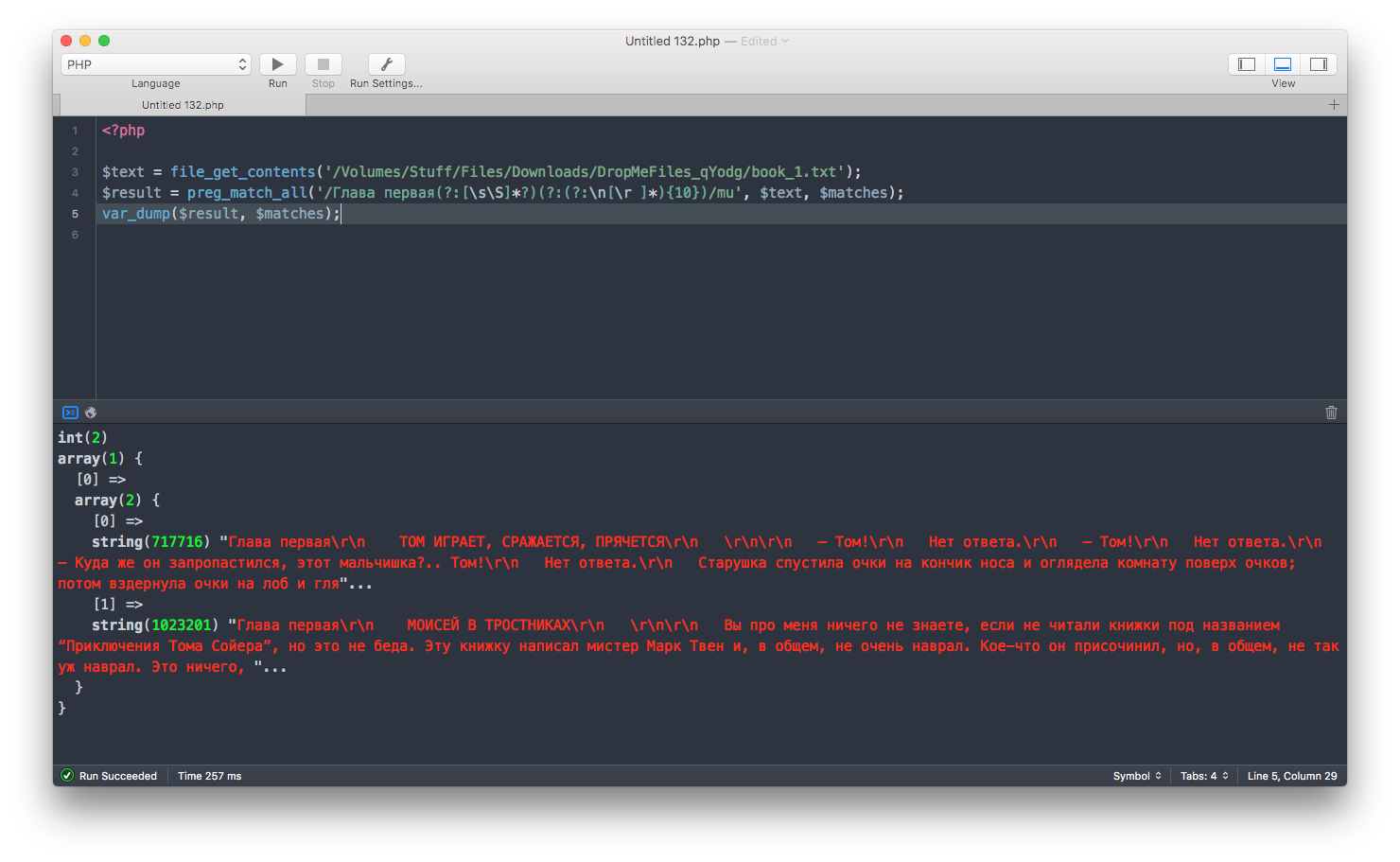
$text = file_get_contents('book_1.txt');
$result = preg_match_all('/Глава первая(?:[\s\S]*?)(?:(?:\n[\r ]*){10})/mu', $text, $matches);
Объясню, что я написал в этой регулярке. Берется слово "Глава первая" и потом любые символы -
[\s\S] бесконечное количество раз
*. Но квантификатор ленивый - это нужно, чтобы поиск остановился на 10 и более переносах строк (между которыми могут быть переносы каретки и пробелы) - так разделяются книги.
Я пробовал использовать этот код на нужной мне книге - возвращается false. Потом я из книги взял только ее часть - файл получится небольшим. И все отлично работает.
Подскажите, пожалуйста, в чем проблема?
Вот файлы:
https://dropmefiles.com/qYodg
book_1.txt - это полноценная книга.
book_2.txt - это небольшой отрывок.
Помогите, пожалуйста, очень интересно, почему так происходит!




 Средний
Средний