Дано:
Некое
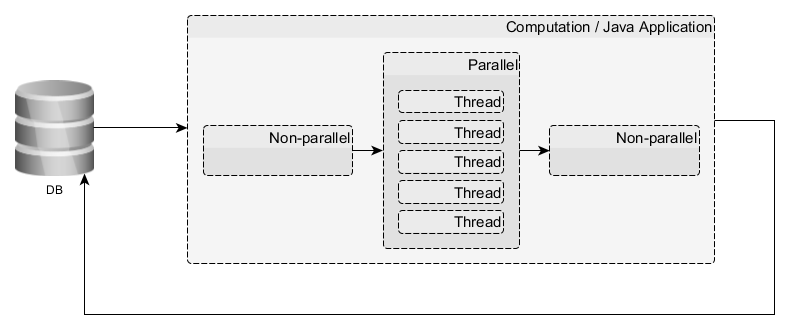
вычислительное (не веб!) приложение на голом Java SE 8, расходующее в процессе работы около 500 Гб RAM и солидную часть ресурсов Intel Xeon E5-2*** и имеющее примерно такую, прости Господи, структуру:
Т. е. один могучий jar-ник запускается на Linux-сервере, тащит к себе комплект данных из БД, которые подвергает неким арифметическим экзекуциям (из которых часть параллелится совсем никак, часть — очень хорошо и сейчас разбита по Thread), и результат отправляется назад в базу.
Само собой, с этим веществом имеются некоторые проблемы:
- Слабая отказоустойчивость (что упало, то запускаем заново)
- Нулевая масштабируемость (варианты «накинуть памяти/процов» скоро перестанут срабатывать)
- Мониторинг только по логам либо — при дебаге — по запущенному VisualVM
- Управление только через параметры командной строки jar-ника и pkill
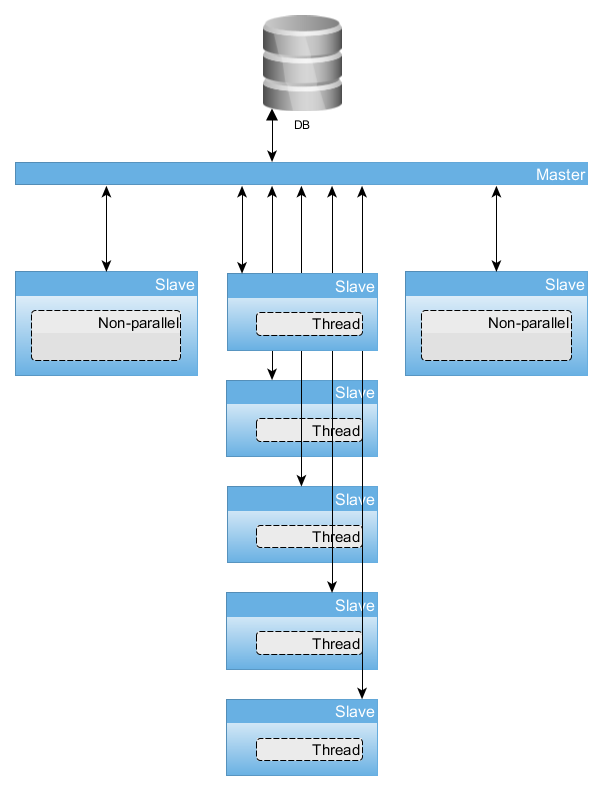
Хотелось бы завернуть это в некий сервер приложений, для управления контроля, балансировки, заодно распределив нагрузку параллельного этапа вычислений на n машин (где n > 1). В моих туманных представлениях новая абстрактная структура приложений должна выглядеть так:
где несчетное количество Slave — отдельные вычислительные машины, которым Master раздает данные (под вопросом. Вероятно, рабы сами могут их затягивать), распределяет нагрузку (если какая-то из машин уже досчитала, ей выдается еще что-нибудь), управляет отказоустойчивостью (один из хостов вышел покурить — перебрасываем его задание на более работающий), агрегирует данные из уже рассчитанных результатов и сбрасывает их в БД.
Но! Но оперативный гуглёж показал, что типичные серверы Java-приложений навроде Wildfly, GlassFish, WebSphere, WebLogic используются именно для обслуживания потребностей
веб-приложений, а для числодробилок нужны монстры в стиле Hadoop, Ignite. Да? Или нет?
Что бы в таком случае применили вы?




 Простой
Простой




