

# Web-page (https://www.weblancer.net/) parser
import urllib.request
from bs4 import BeautifulSoup
def get_html(url):
response = urllib.request.urlopen(url)
return response.read()
def parse(html):
soup = BeautifulSoup(html)
table = soup.find("table", clazz="items_list")
print(table)
def main():
parse(get_html("https://www.weblancer.net/projects/"))
if __name__ == "__main__":
main()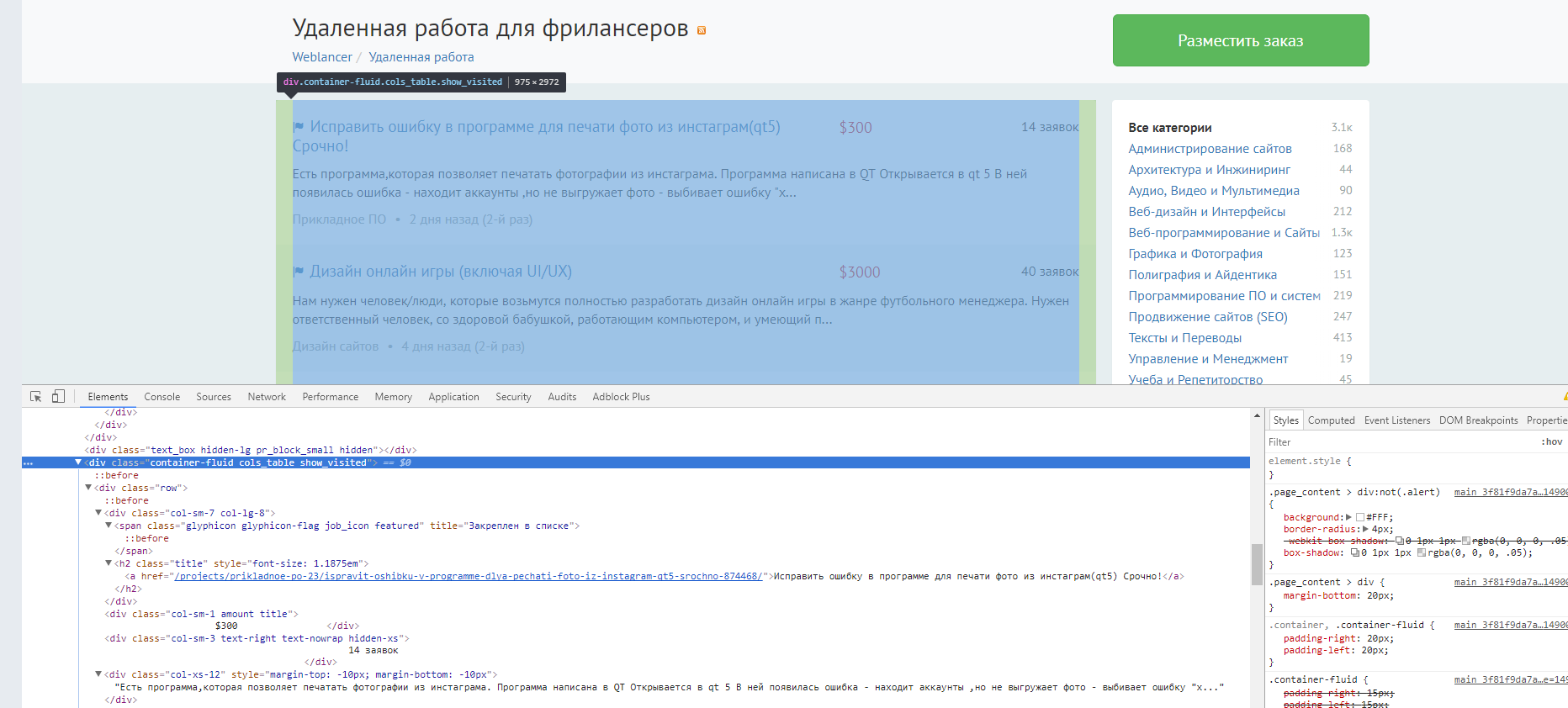

from bs4 import BeautifulSoup
content_table = """
<table>
<thead>
<th>ID</th>
<th>Vendor</th>
<th>Product</th>
</thead>
<tr>
<td>1</td>
<td>Intel</td>
<td>Processor</td>
</tr>
<tr>
<td>2</td>
<td>AMD</td>
<td>GPU</td>
</tr>
<tr>
<td>3</td>
<td>Gigabyte</td>
<td>Mainboard</td>
</tr>
</table>
"""
soup = BeautifulSoup(content_table, 'html.parser')
headers = {}
rows = soup.find_all("tr")
thead = soup.find("thead").find_all("th")
for i in range(len(thead)):
headers[i] = thead[i].text.strip().lower()
data = []
for row in rows:
cells = row.find_all("td")
item = {}
for index in headers:
item[headers[index]] = cells[index].text
data.append(item)
print(data)for row in response.xpath('//table[@id="table1"]/tr'):
item['name'] = row.xpath('./td[1]/text()').extract_first()
yield item Средний
Простой
Сложный
Средний
Простой
Сложный