
names = pd.concat(pieces,ignore_index = True)
a=names['name'].unique()
b=list(a)
q=[]
for n in b:
q.append(fuzzy.nysiis(n))
df=pd.DataFrame(b)
df1=pd.DataFrame(q)
w=df.join(df1, how='left', lsuffix='_left', rsuffix='_right')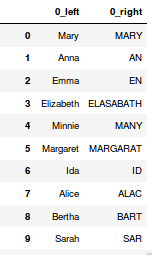
 Простой
Простой
Простой
Простой
Простой
Простой
 Простой
Простой
 Простой
Простой
Простой
Простой