Всем привет.
Я пытаюсь разгрузить один запрос или думаю вообще переделать архитектуру хранения записей. Надеюсь вы мне поможете определиться ;)
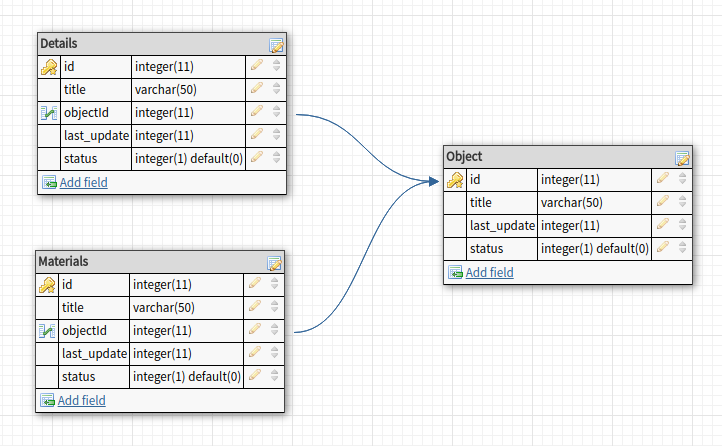
На проекте есть 3 таблицы:
Объект, к которым принадлежат
Детали и
Материалы. Мне нужно получить: Список объектов, у которых есть кол-во (
items_count) принадлежащих к нему Детали+Материалы, а так же получить последнюю дату обновлению записи, т.е. пройтись по этим таблицам (по полю
last_update) и вытащить последнюю таймстамп дату GREATEST() .
Поле status = 1 , item доступен или нет. SELECT
`Ob`.`id` AS `id`,
`Ob`.`title` AS `title`,
`Ob`.`poster` AS `poster` ,
@count_details := (SELECT count(*) FROM game.Details D WHERE D.objectId = Ob.id AND D.status = 1 ),
@count_materials := (SELECT count(*) FROM game.Materials Ma WHERE Ma.objectId = Ob.id AND Ma.status = 1 ),
@count_details + @count_materials as items_count,
@max_update_details := (SELECT MAX(D.last_update) FROM game.Details D WHERE D.objectId = Ob.id AND D.status = 1 ),
@max_update_materials := (SELECT MAX(Ma.last_update) FROM game.Materials Ma WHERE Ma.objectId = Ob.id AND Ma.status = 1 ),
GREATEST(
`Ob`.`last_update`, @max_update_details, ifnull(@max_update_materials, 0 )
) as last_update
FROM game.`Object` Ob
WHERE status=1
ORDER BY last_update DESC;
В принципе все это работает, но проблема в том, что это чудо долго будет обрабатываться с нарастанием записей. :(
Реально ли как-то оптимизировать этот запрос?
Я думаю, что при сохранении формы добавления/изменения Details или Materials пересчитывать их кол-во к принадлежащему объекту. И заносить в Object таблицу, в какую нибудь новую колонку, а не делать каждый раз столько вложенных запросов. Тоже самое и касается время изменения last_update.
Еще наткнулся на один
вопрос, где во вложенном запросе добавлена переменная @i в качестве инкремента. Можно ли сделать, чтобы на момент вычисления максимального значения, можно было подсчитать кол-во найденных записей, (псевдокод):
SELECT MAX(D.last_update), @i := @i +1
FROM game.Details D
WHERE D.objectId = Ob.id;
Забыл кстати скинуть результаты Explain:
id |select_type |table |type |possible_keys |key |key_len |ref |rows |Extra |
---|-------------------|------|-----|------------------------------------------|------------------------------|--------|------|-------|---------------------------------------------|
1 |PRIMARY |Ob |ALL | | | | |139 |Using where; Using temporary; Using filesort |
5 |DEPENDENT SUBQUERY |D |ref |IX_Details_status_last_update |IX_Details_status_last_update |2 |const |25909 |Using where |
4 |DEPENDENT SUBQUERY |Ma |ref |IX_Materials_status,IX_Materials_objectId |IX_Materials_status |2 |const |125431 |Using where |
3 |DEPENDENT SUBQUERY |D |ref |IX_Details_status_last_update |IX_Details_status_last_update |2 |const |25909 |Using where |
2 |DEPENDENT SUBQUERY |Ma |ref |IX_Materials_status,IX_Materials_objectId |IX_Materials_status |2 |const |125431 |Using where |
Вот схема Таблиц:
Спасибо за внимание!





