string pathToHtml = "ссылка";
WebClient client = new WebClient();
var data = client.DownloadData(pathToHtml);
var html = Encoding.UTF8.GetString(data);
// Создание экземпляра локальной переменной «doc».
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
// Загрузка HTML кода в локальную переменную «doc».
doc.LoadHtml(html);
var x = doc.DocumentNode.SelectNodes("XPATH выражение").Elements("tr").ToList();WebClient не поддерживается в .NET Core: stackoverflow.com. Для .NET Core нужно (возможно не обязательно) использовать HttpClient.
using System;
using System.IO;
using System.Net;
using System.Net.Http;
using System.Text.RegularExpressions;
using System.Threading.Tasks;
namespace ConsoleApplication3
{
public static class Program
{
private static string html = "Ошибка";
private static void Main()
{
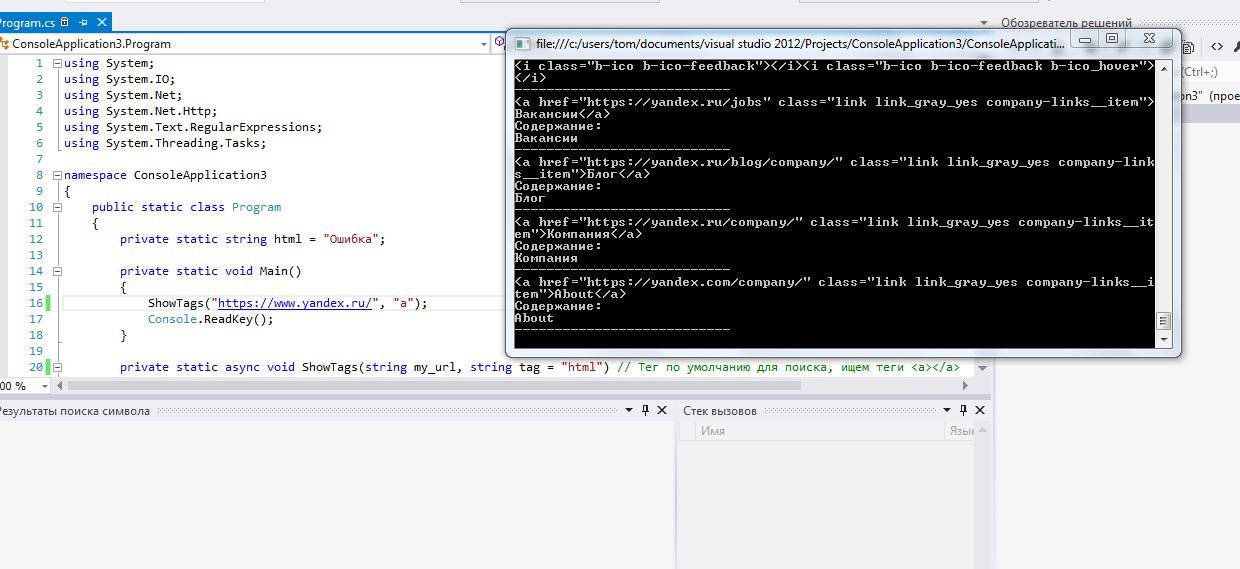
ShowTags("https://www.yandex.ru/","a");
Console.ReadKey();
}
private static async void ShowTags(string my_url, string tag = "a") // Тег по умолчанию для поиска, ищем теги <a></a>
{
// Загружем страницу
string data = await GetHtmlPageText(my_url);
if (!data.Contains("Ошибка"))
{
string pattern = string.Format(@"\<{0}.*?\>(?<tegData>.+?)\<\/{0}\>", tag.Trim());
// \<{0}.*?\> - открывающий тег
// \<\/{0}\> - закрывающий тег
// (?<tegData>.+?) - содержимое тега, записываем в группу tegData
Regex regex = new Regex(pattern, RegexOptions.ExplicitCapture);
MatchCollection matches = regex.Matches(data);
foreach (Match matche in matches)
{
Console.WriteLine(matche.Value);
Console.WriteLine("Содержание:");
Console.WriteLine(matche.Groups["tegData"].Value);
Console.WriteLine("---------------------------");
}
}
else
{
Console.WriteLine("Ошибка при загрузке со страницы: " + my_url);
}
}
private static async Task<string> GetHtmlPageText(string url)
{
await Task.Run(async()=>{
// ... используем HttpClient.
using (HttpClient client = new HttpClient())
using (HttpResponseMessage response = await client.GetAsync(url))
using (HttpContent content = response.Content)
{
// ... записать ответ
string result = await content.ReadAsStringAsync();
if (html != null)
{
html = result;
}
}
});
return html;
}
}
}<a href="http://mail.yandex.ru"onclick="c(this,17,1080)">Войти в почту</a>
Содержание:
Войти в почтуHttpWebRequest получилось сделать:HttpWebRequest http = (HttpWebRequest)WebRequest.Create(pathToHtml);
WebResponse response = http.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader sr = new StreamReader(stream);
string html = sr.ReadToEnd();
// Создание экземпляра локальной переменной «doc».
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
// Загрузка HTML кода в локальную переменную «doc».
doc.LoadHtml(html);
var x = doc.DocumentNode.SelectNodes(pathToHTMLTextNode).Elements("tr").ToList(); Простой
Простой
 Простой
Простой
Простой
Простой
Простой
Простой