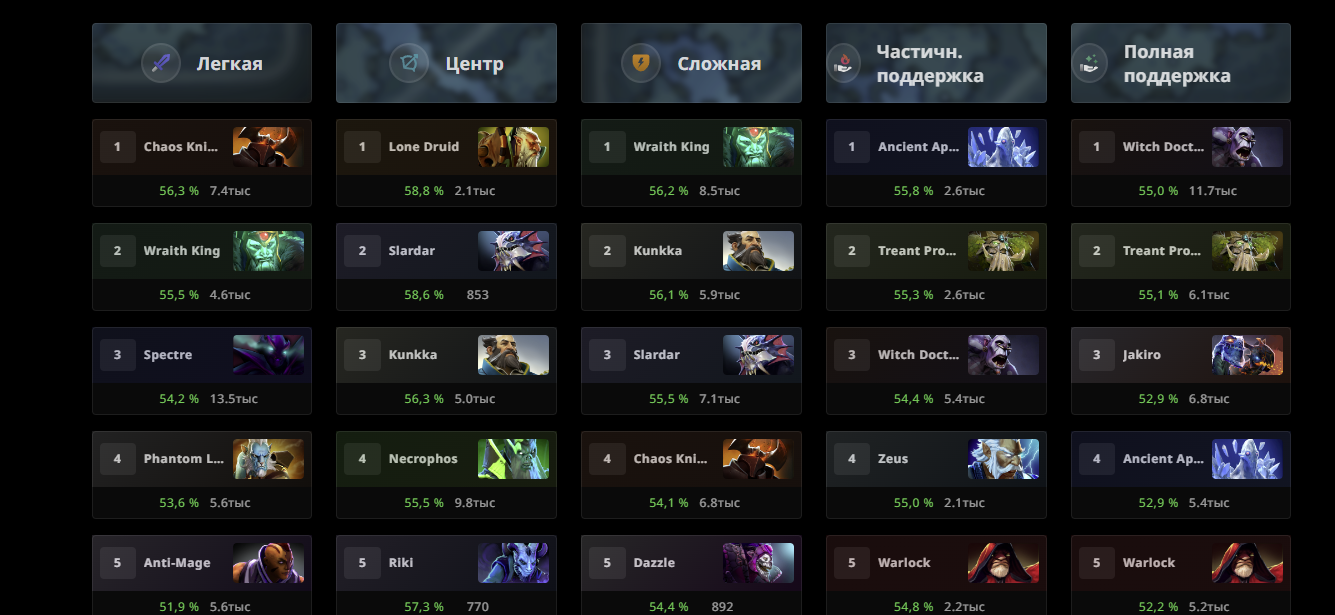
Что именно я делаю не так
используешь максимально неподходящий инструмент для задачи
Твои данные подгружаются на javascript после, изучай в консоли разработчика в браузере, открой вкладку network и смотри.
Разработчики сайта борются с автоматизацией, будет не просто. Ссылки и даже данные в них меняются, стили меняются. Может там еще какие то методики используются (например повторный запрос с теми же заголовками возвращает уже другие данные без искомых).
Самое простое, используй симулятор браузера, любыми инструментами (например selenium под любимый язык), модифицированные стили обходи поиском по относительной позиции и значению, в общем объяснять долго и нудно.