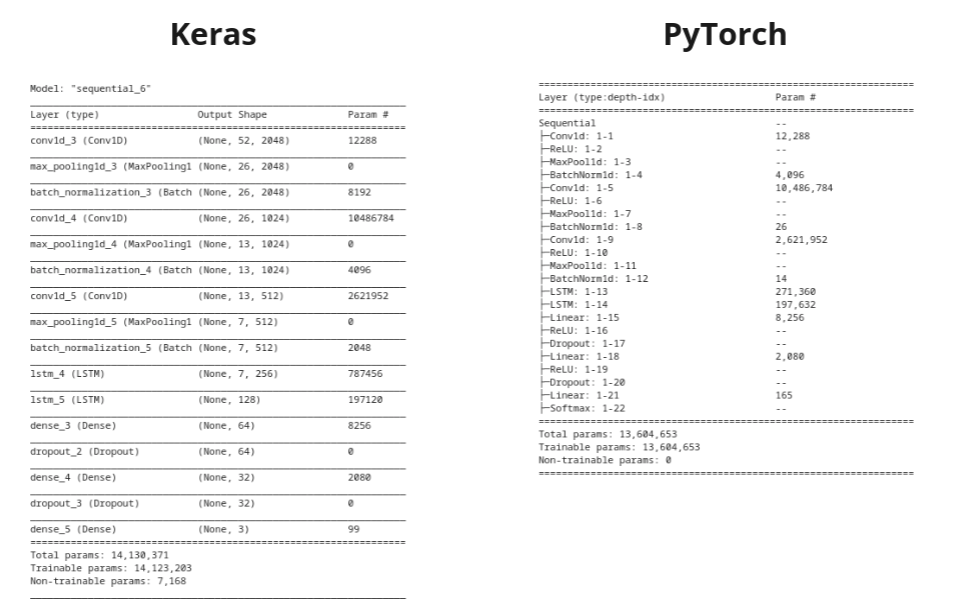
Я переписываю модель нейронной сети с keras на pytorch
Все было хорошо, пока я не добрался до блоков LSTM. Заранее извиняюсь, если я что-то упустил и вопрос оказался глупым. И ещё, Sequential модель - для примера (такой вариант для pytorch не будет работать, но это не важно). Когда я попытался переписать сетку в pytorch, я заметил:
- Количество параметров не совпадает
- выходные значения keras и pytorch LSTM отличаются
Я не могу понять, как последний слой LSTM в keras выдает форму [batch_size, 128], потому что до этого на входе была последовательность длиной 256 с 7 признаками. PyTorch LSTM возвращает
output, (hidden_state, cell_state), где
output — это результат вычисления последнего слоя для каждого временного шага (каждое векторное представление слова в предложении). Я считаю, что для задачи классификации мне нужен не каждый временной шаг, а только результат вычислений с последнего временного шага. Правда ли, что когда аргумент return_sequences=True в keras LSTM, то нам возвращается результат для последнего временного шага (
hidden_state)? Тогда это объясняет выходную ворму
batch_size, 128, где
batch_size - размер пакета, а
128 - количество признаков на выходе LSTM блока.
Keras
lstm_keras = Sequential()
lstm_keras.add(Conv1D(2048, kernel_size=5, strides=1, padding='same', activation='relu', input_shape=(52, 1)))
lstm_keras.add(MaxPooling1D(pool_size=2, strides = 2, padding = 'same'))
lstm_keras.add(BatchNormalization())`
lstm_keras.add(Conv1D(1024, kernel_size=5, strides=1, padding='same', activation='relu', input_shape=(52, 1)))
lstm_keras.add(MaxPooling1D(pool_size=2, strides = 2, padding = 'same'))
lstm_keras.add(BatchNormalization())`
lstm_keras.add(Conv1D(512, kernel_size=5, strides=1, padding='same', activation='relu'))
lstm_keras.add(MaxPooling1D(pool_size=2, strides = 2, padding = 'same'))
lstm_keras.add(BatchNormalization())`
lstm_keras.add(LSTM(256, return_sequences=True))
lstm_keras.add(LSTM(128))`
lstm_keras.add(Dense(64, activation='relu'))
lstm_keras.add(Dropout(0.5))
lstm_keras.add(Dense(32, activation='relu'))
lstm_keras.add(Dropout(0.5))`
lstm_keras.add(Dense(3, activation='softmax'))
lstm_keras.summary()`
Pytorch
lstm_torch = nn.Sequential(
nn.Conv1d(in_channels=1, out_channels=2048, stride=1, kernel_size=5, padding=2),
nn.ReLU(),
nn.MaxPool1d(kernel_size=2, stride=2),
nn.BatchNorm1d(26),
nn.Conv1d(in_channels=2048, out_channels=1024, stride=1, kernel_size=5, padding=2),
nn.ReLU(),
nn.MaxPool1d(kernel_size=2, stride=2),
nn.BatchNorm1d(13),
nn.Conv1d(in_channels=1024, out_channels=512, stride=1, kernel_size=5, padding=2),
nn.ReLU(),
nn.MaxPool1d(kernel_size=2, stride=2, padding=1),
nn.BatchNorm1d(7),
nn.LSTM(input_size=7, hidden_size=256),
nn.LSTM(input_size=256,hidden_size=128),
nn.Linear(128, 64),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(64, 32),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(32, 3),
nn.Softmax()
)
Но это не объясняет, почему в моей сети в слоях pytorch LSTM гораздо меньше параметров, чем при записи в keras: