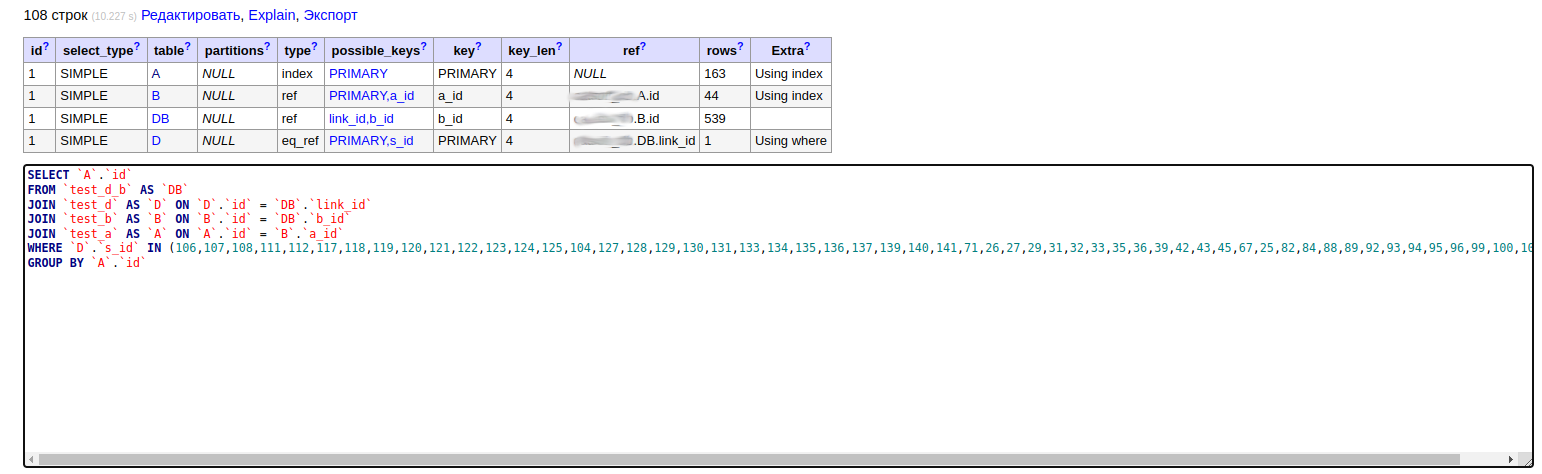
1. Получить записи из справочника "
A" с учётом переданных ID'шников из справочника "
S" и наличия в таблице
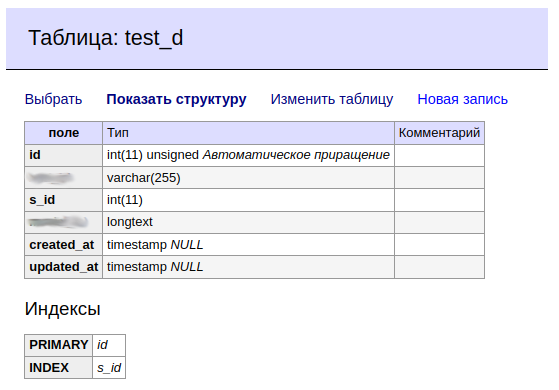
D.
Кол-во ID'шников для фильтра может быть любым - чаще больше 40.
Тут логично с помощью JOIN соединить
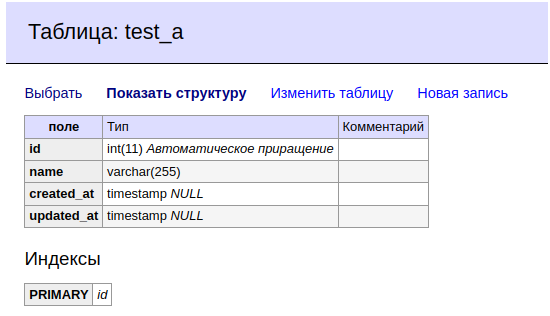
A,
B и
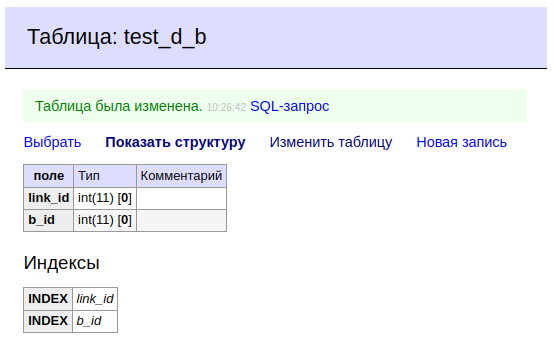
D.
 2.
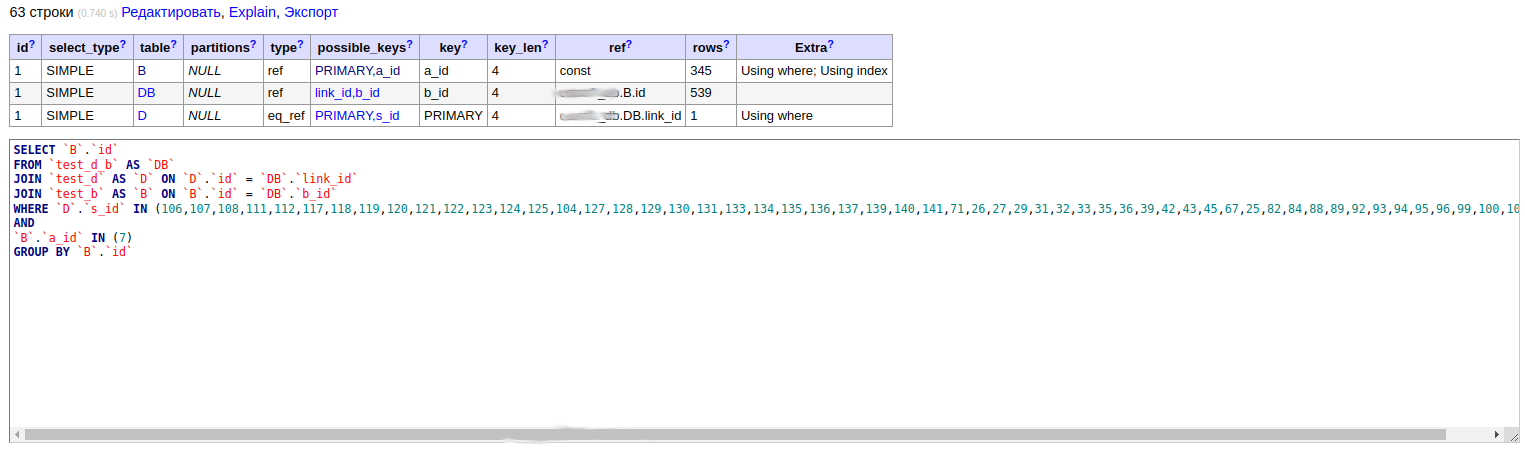
2. Получить записи из справочника "
B" с учётом переданных ID'шников из справочника "
S" и справочника "
A", и наличия в таблице
D.
Кол-во ID'шников(
S) для фильтра может быть любым - чаще больше 40.
Кол-во ID'шников(
A) для фильтра может быть от 1 до 2 - чаще 1.
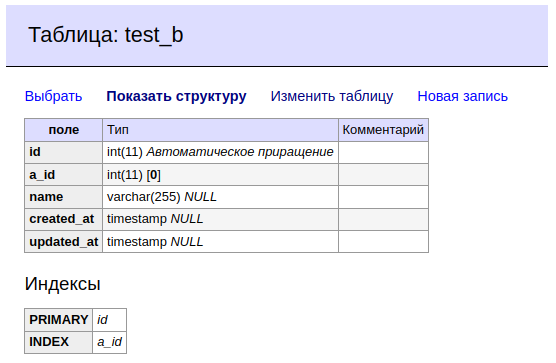
Тут, опять же, логично с помощью JOIN соединить
A,
B и
D.
 3.
3. Получить записи из справочника "
C" с учётом переданных ID'шников из справочника "
S" и справочника "
B", и наличия в таблице
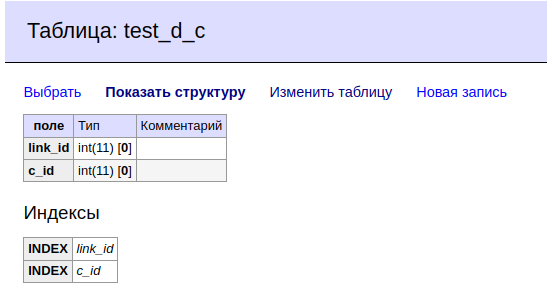
D.
Кол-во ID'шников(
S) для фильтра может быть любым - чаще больше 40.
Кол-во ID'шников(
B) для фильтра может быть от 1 до 10 - чаще 1.
Тут, опять же, логично с помощью JOIN соединить
B,
C и
D.
4. Получить записи из таблицы "
D" с учётом переданных ID'шников из справочника "
S", справочника "
B" и справочника
C.
Кол-во ID'шников(
S) для фильтра может быть любым - чаще больше 40.
Кол-во ID'шников(
B) для фильтра может быть от 1 до 10 - чаще 1.
Кол-во ID'шников(
C) для фильтра может быть от 1 до 5 - чаще 1.
Тут, опять же, логично с помощью JOIN соединить
B,
C и
D.






 Средний
Средний
 Простой
Простой
 Средний
Средний