Нужно спарсить ссылки с этого страницы
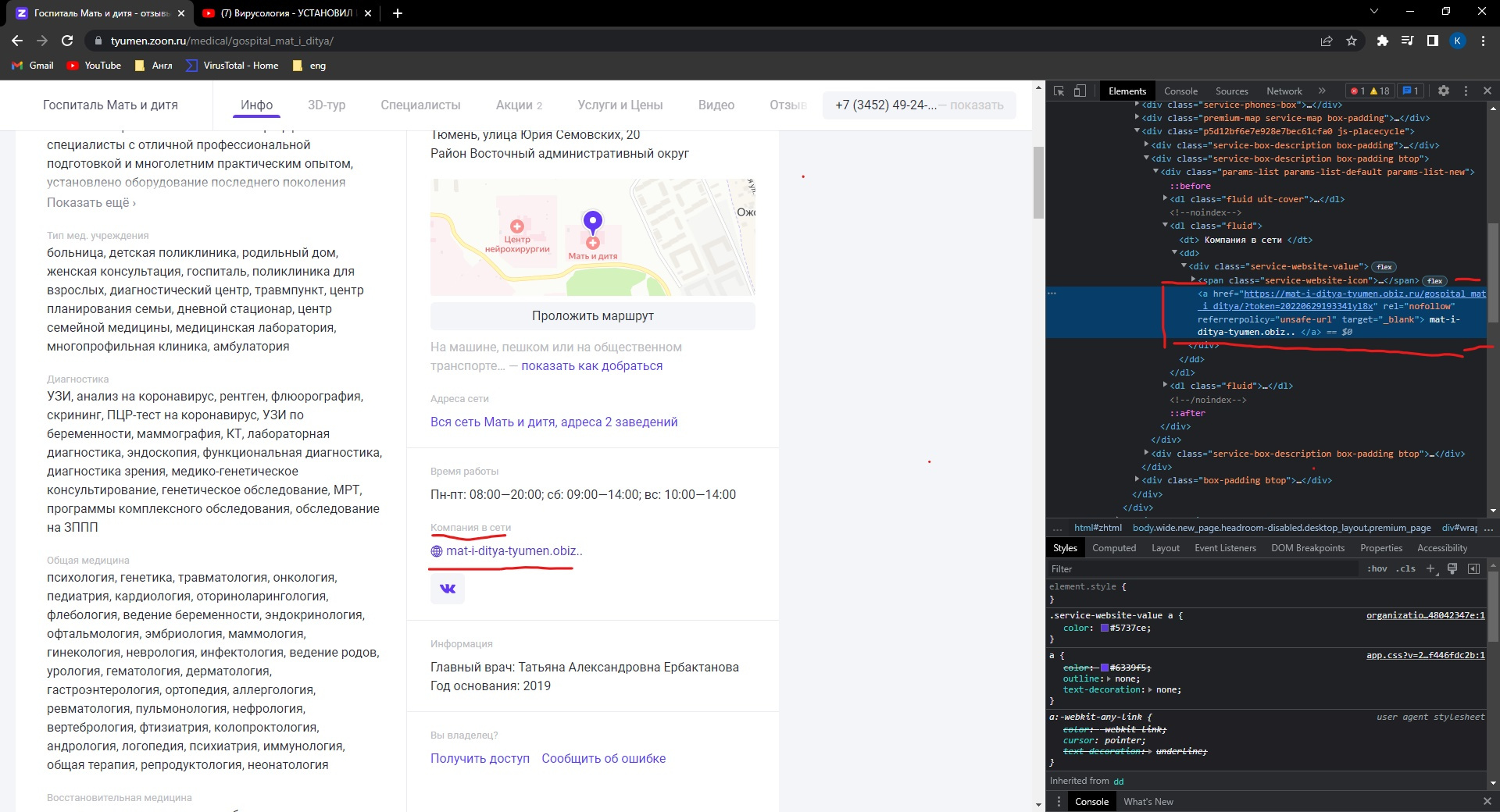
https://tyumen.zoon.ru/medical/gospital_mat_i_ditya/ А именно блок под названием "Компания в сети". Мне нужна ссылка на их сайт и желательно ссылка на соцсети. Вот как это сделал я (здесь я пытаюсь спарсить ИМЕННО ссылку на сайт)
from urllib import response
from isort import file
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
import time
import re
headers = {
"Accept": "*/*",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
def get_source_html(url):
chrome_options = Options() # новое обновление selenium
driver = Service(executable_path="C:\\webdrivers\\chromedriver.exe") # новое обновление selenium
driver = webdriver.Chrome(options=chrome_options) # новое обновление selenium
driver.maximize_window() # открывает на полный экран окно браузера
try:
driver.get(url=url)
time.sleep(3)
while True:
find_more_element = driver.find_element(
By.CLASS_NAME, "catalog-button-showMore") # новое обновление selenium
if driver.find_elements(By.CLASS_NAME, "hasmore-text"): # новое обновление selenium
with open("source-page.html", "w") as file:
file.write(driver.page_source)
break
else:
actions = ActionChains(driver)
actions.move_to_element(find_more_element).perform()
time.sleep(3)
except Exception as ex:
print(ex)
finally:
driver.close()
driver.quit()
def get_items_urls(file_path):
with open (file_path) as file:
src = file.read() # хз че это, потом погуглю
soup = BeautifulSoup(src, "lxml")
minecards_items = soup.find_all("div", class_= "minicard-item__info") # поиcк первого класса
urls = []
for item in minecards_items:
item_url = item.find("h2", class_="minicard-item__title").find("a").get("href") # ищем нужные классы для одной больницы # поиск вторго класса
urls.append(item_url)
with open("items_urls.txt", "w") as file: # сохраняем все ссылки
for url in urls:
file.write(f"{url}\n")
return "[INFO] Succesfully" # успешая згрузка в txt файл
def get_data(file_path):
with open (file_path) as file:
urls_list= [url.strip()for url in file.readlines()] # тоже убирает перенос строки,только более короткий способ
for url in urls_list[:1]:
response = requests.get( url=url, headers=headers)
soup = BeautifulSoup(response.text,"lxml")
try:
item_name = soup.find("span", {"itemprop":"name"}).text.strip()# ищем span с названием больниц
except Exception as _ex:
item_name =None
item_phones_list =[]
try:
item_phones= soup.find("div",class_="service-phones-list").find_all("a", class_="js-phone-number") # ищем нужные классы с номерами телефонов
for phone in item_phones:
item_phone = phone.get("href").split(":")[-1].strip() # находим ссылку, разделяем двоеточием, убираем пробелы
item_phones_list.append(item_phone) #наполянем список на каждой иттерации
except Exception as _ex:
item_phones_list =None
try:
item_address = soup.find("address", class_="iblock").text.strip()# ищем class с адрессом больниц
except Exception as _ex:
item_address =None
try:
item_site = soup.find("div", class_="service-website-value").find("span", class_="service-website-icon").find("svg", class_="svg-icons-website").find_all("a", "href") # ищем class с сайтом больниц ВОТ ОНО
except Exception as _ex:
item_site = None
print(item_name, item_phones_list, item_address, item_site)
def main():
#get_source_html(url = "https://tyumen.zoon.ru/medical/type/detskaya_poliklinika/")
#print(get_items_urls(file_path="C:\\Users\Константин\Downloads\dodit\source-page.html"))
get_data(file_path="C:\\Users\Константин\Downloads\dodit\items_urls.txt")
if __name__ == "__main__":
main()
ВНИМАНИЕ НА ПОСЛЕДНЕ try execpt там все нужное
что выводится
Госпиталь Мать и дитя ['+73452492431'] Тюмень, улица Юрия Семовских, 20 []

