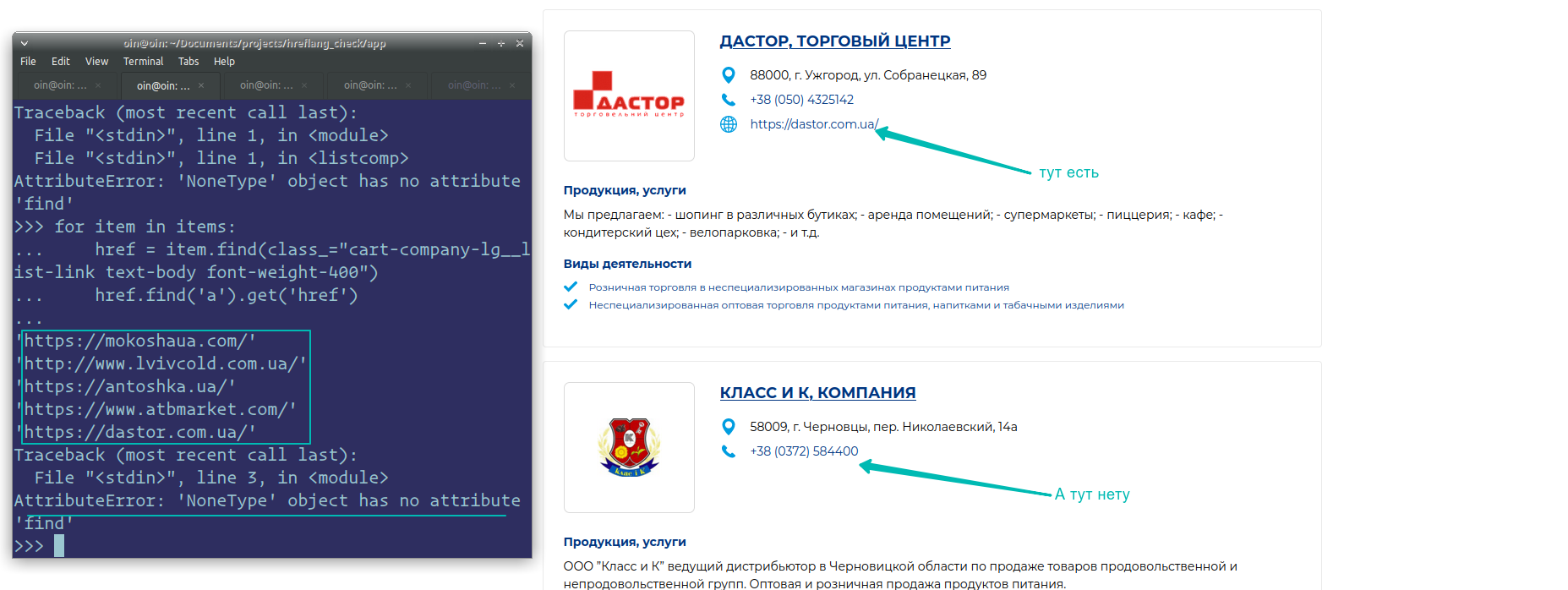
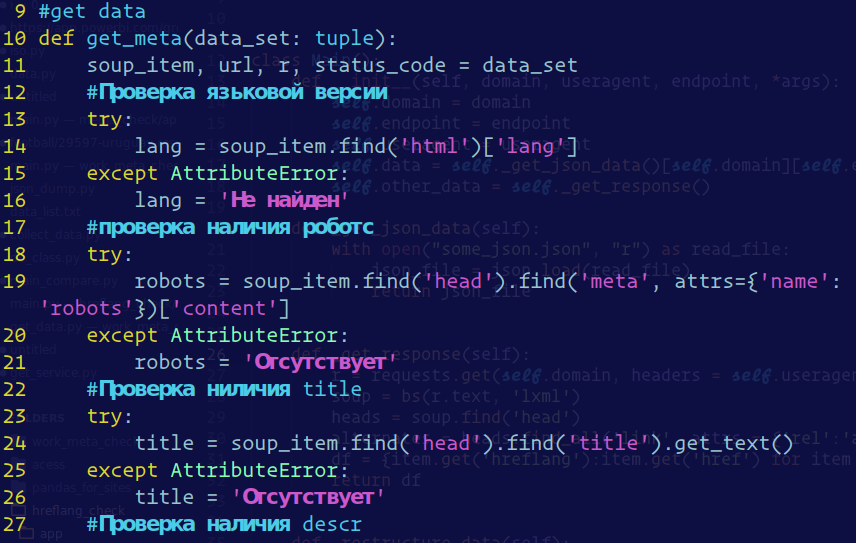
В личных целях нужно спарсить сайт. Уперся в вытаскивание ссылок и почты (нужно, чтоб данные были пригодны для дальнейшей работы с ними).
Вот что есть:
import lxml
import requests
from bs4 import BeautifulSoup
import csv
CSV = "companys.csv"
HOST = 'https://www.ua-region.com.ua'
URL = 'https://www.ua-region.com.ua/ru/kved/47.11'
HEADERS = {
"Accept": "*/*",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0"
}
def get_html(url, params=''):
r = requests.get(url, headers=HEADERS, params=params)
return r
def get_content(html):
soup = BeautifulSoup(html, 'lxml')
items = soup.find_all(class_="cart-company-lg d-flex flex-wrap rounded mb-3 border")
company = []
for item in items:
company.append(
{
"title":item.find(class_="cart-company-lg__title ui-title-inner").get_text(),
"link":item.find(class_="cart-company-lg__list-link text-body font-weight-400"),
"adres":item.find(class_="cart-company-lg__list-link").get_text(),
"phone":item.find("a", class_="text-nowrap").attrs['href'],
"mail":item.find(attrs={"target": "_blank"}),
"subtitle":item.find(class_="col-12 mt-mb-0").get_text()
}
)
return company
def save_data(items, path):
with open(path, "w", newline="") as file:
writer = csv.writer(file, delimiter=";")
writer.writerow(["Name", "Link", "Adres", "Phone", "Mail", "Subtitle"])
for item in items:
writer.writerow([item["title"], item["link"], item["adres"], item["phone"], item["mail"], item["subtitle"]])
def parser():
PAGINATION = input("Кол-во страниц: ")
PAGINATION = int(PAGINATION.strip())
html = get_html(URL)
if html.status_code == 200:
companys = []
for start_page in range(1, PAGINATION+1):
print(f"Pasce page: {start_page}")
html = get_html(URL, params={"start_page": start_page})
companys.extend(get_content(html.text))
save_data(companys, CSV)
pass
else:
print("Error")
parser()
Все вытаскивается нормально, кроме линков и мейлов. Они в таком виде:
span class="cart-company-lg__list-link text-body font-weight-400">
https://mokoshaua.com/ ,
https://www.facebook.com/MokoshaCheese ,
https://www.instagram.com/mokosha_cheese/
a href="mailto:mokosha@i.ua" target="_blank">mokosha@i.ua
Не понимаю, почему в "link":item.find(class_="cart-company-lg__list-link text-body font-weight-400"), # get('href') возвращает None. Вроде не должен бы ...
Почитал про скрипт JS добавление mailto. Но как его в данный контекст прикрутить не понимаю.
Спасибо