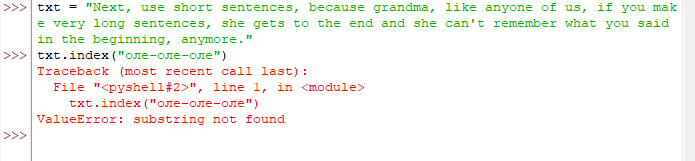
Здравствуйте! Возможно, что задал коряво вопрос, извиняюсь, только изучаю это все :)
Есть длинная строка, которая содержит много слов, к примеру: 'Next, use short sentences, because grandma, like anyone of us, if you make very long sentences, she gets to the end and she can't remember what you said in the beginning, anymore.'
Не конкретно эта, количество символов в строке может быть случайным.
У меня так же есть слово A и слово B.
Суть в том, что мне нужно проверить, находится ли в строке слово A после слова B, или же наоборот, в зависимости от этого вывести на экран разные вещи. То есть:
If слово A в строке стоит после B: Print ('После')
Else: print ('До')
txt = "Next, use short sentences, because grandma, like anyone of us, if you make very long sentences, she gets to the end and she can't remember what you said in the beginning, anymore."
try:
A = txt.index("remember")
B = txt.index("grandma")
if int(A) - int(B) < 0:
print('Слово A находится до слова B')
else:
print('Слово A находится после слова B')
except ValueError:
print('Не найдено как минимум одно из слов в строке')
Любой метод поиска подстроки в строке (хоть str.index(), хоть регулярные выражения) возвращает позицию найденного слова.
Нашёл позицию одного слова, нашел позицию другого, сравнил два числа.