[mysqld]
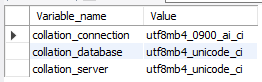
init_connect='SET collation_connection = utf8mb4_unicode_ci'
collation-server=utf8mb4_unicode_ci-v /local/path/to/hosts/config/collation.conf:/etc/my.cnf.d/collation.conf Средний
Средний
 Средний
Средний
 Простой
Простой