Во-первых, НИКОГДА не мешайте многопоточность с асинхронностью. Асинхронность придумали для того, чтобы не делать потоки.
Если я правильно понял, то Вы хотите сделать программу, которая проверяет работоспособность множества сайтов одновременно.
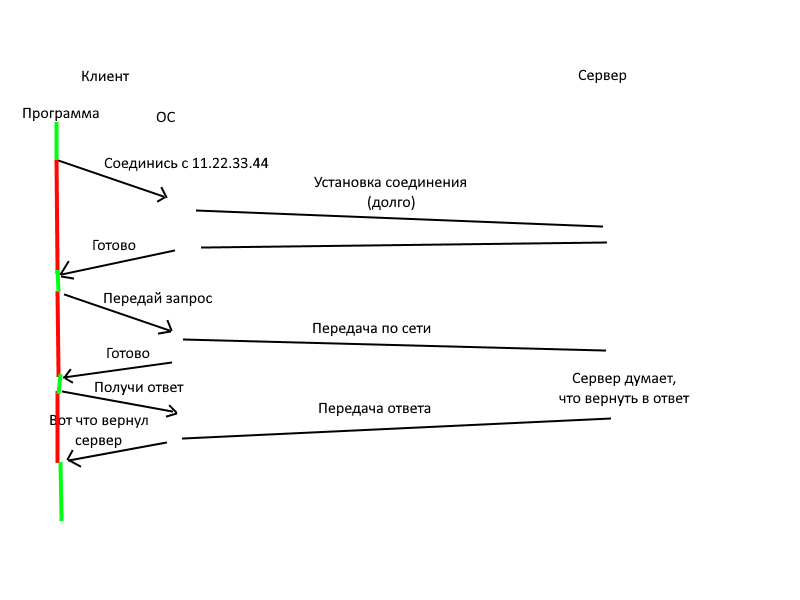
Смотрите:
Как можно увеличить либо число потоков, либо просто число проверок за раз?
Делайте несколько "воркеров" - то есть просто запускайте программу несколько раз. НО делать это на одном устройстве все равно скорее всего не будет никакого смысла, так как основная нагрузка будет на сеть, а не на процессор.
Предварительно я их распихиваю по нескольким серверам, к примеру 5 шт. Значит на один сервер выходит 20 тысяч за раз. Все эти задачи сначала попадают в свои БД, на своих серверах, а потом их можно сливать в одну общую таблицу. Но можно и читать данные из разных серверов ...
Вот именно так. Но базу данных можно делать одну на все сервера (sqlite не подойдет, mysql или postgreesql будут не плохим вариантом). Вы делаете основной сервер, где будет БД и 1 воркер и множество доп. серверов с 1 воркером на каждом, которые подключаются к БД на основном.
Дальше стоит понять, чем асинхронный запрос отличается от синхронного.
(максимально упрощенно, обычно все сложнее).
1. Синхронный: все время, отмеченное красным программа не работает, Ваша ОС приостанавливает ее выполнение. Получается, что программа одновременно может выполнять лишь один запрос, при этом большую часть времени она ничего не делает.
2. Асинхронный: ОС сразу возвращает ответ, типа "будет сделано" и программа может работать дальше. Но вам ведь нужен конкретный ответ, поэтому asyncio пока ждет ответа от ОС (которая ждет ответа от сервера), может выполнять другие задачи (например, начинать другие запросы). Теперь ваша программа может делать несколько запросов одновременно, их количество зависит уже от ОС и сети.
Как правильно учесть вариант того, что страницы могут задерживать ответ, таймаут, но насколько грамотное это решение получиться?
ОС будет сама отслеживать таймауты для каждого запроса отдельно. Таймаут можно указать руками при создании запроса, если этого не сделать, то он будет равен 5 минут (что для синхронного запроса ооочень много, но для асинхронного сойдет). Про таймаут можно почитать
в документации.
Про задачи в asyncio. Чтобы выполнить несколько функций (псево)параллельно используется функция asyncio.gather():
async def make_request(address):
...
return address, response # чтобы потом можно было понять, на что это ответ
async def main():
urls = [...]
reqs = []
for url in urls:
reqs.append(make_request(url)) # Обратите внимание на отсутствие await, нам не нужно ждать завершения сейчас
results = await asyncio.gather(reqs) # gather объединяет несколько корутин в одну, теперь мы ждем, пока выполнятся все запросы
# теперь results - list[tuple[<address>, <response>]]
for url, result in results:
print(...) # print можно делать и в обработчике, тут уже зависит от того, что вы хотите сделать с ответом
Есть и другие способы запуска задач (ensure_future и create_task, возможно они вам больше подойдут).
Как правильно обрабатывать ответы, если будет приходить много данных за раз?
Каждый ответ обрабатывайте отдельно. Прямо сразу после запроса (в примере в функции make_request).
Вот пример из документации.
Когда пишете код с aiohttp не забывайте, что
async with session.get(...) as resp: и есть запрос. async with по сути внутри себя содержит await, поэтому пока выполняется такой код может выполниться еще несколько параллельных задач.
Еще отлаживать асинхронный код довольно сложно, поэтому используйте логирование (можно начать с обычных print-ов, только не print("xx") и print("yy"), а print(f"Starting request to {url}...") и print(f"Got response from {url}...") - иначе вы не сможете понять, какой сайт долго отвечает, сколько по времени выполняется запрос к 1 сайту (тут поможет logging и метки времени) и на каком количестве запросов программа виснет).