Если я правильно понимаю ваш вопрос, то вам нужно создать нечто подобное:
Пример
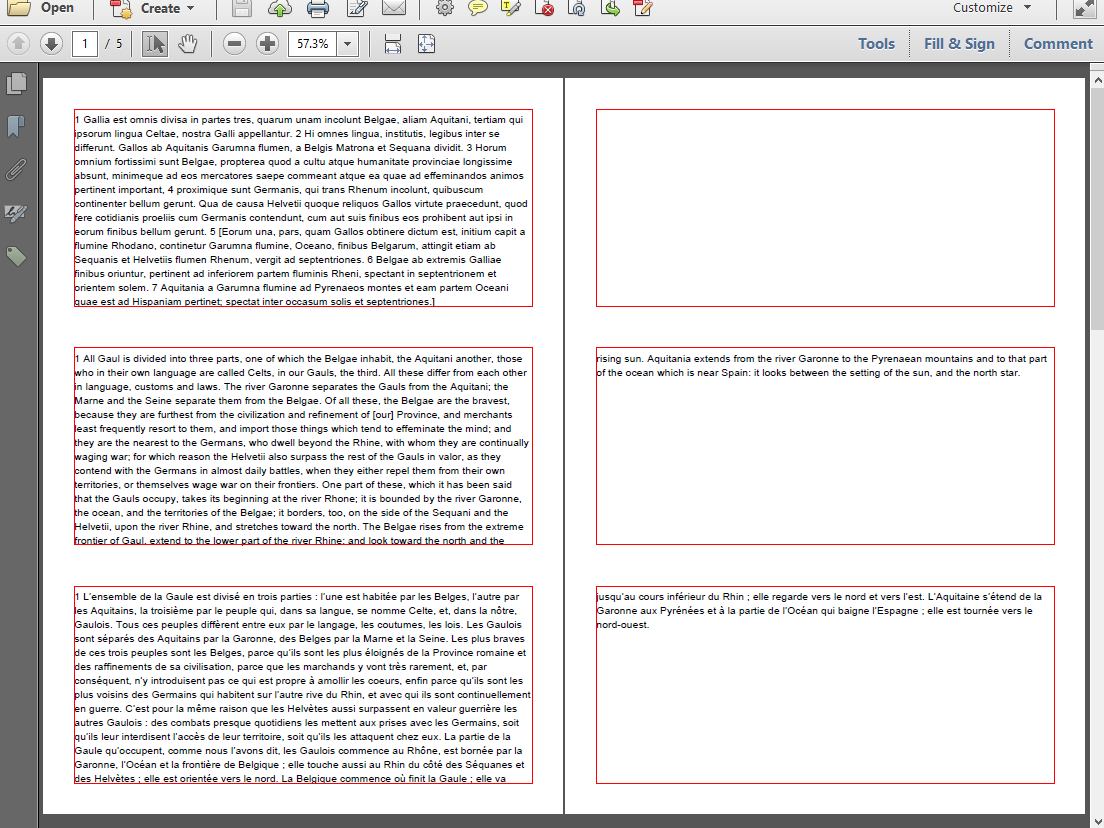
На этом скриншоте показана первая часть первой книги «Записки о Гальской войне» Цезаря. Gallia omnia est divisa in partes tres, каждая страница разделена в следующем порядке: верхняя часть содержит текст на латинском, средняя часть — на английском, а нижняя часть — на французском. Если вы прочитаете текст, то обнаружите, что бельгийцы (а я бельгиец) — самый храбрый народ (хотя мы и не такие цивилизованные, как хотелось бы). Посмотрите документ
three_parts.pdf, чтобы ознакомиться с примером PDF-файла.
Этот PDF-файл создан с примером
ThreeParts. В этом примере есть 9 текстовых файлов:
liber1_1_la.txt,
liber1_1_en.txt,
liber1_1_fr.txt,
liber1_2_la.txt,
liber1_2_en.txt,
liber1_2_fr.txt,
liber1_3_la.txt,
liber1_3_en.txt и
liber1_3_fr.txt.
«Liber» с латыни переводится как «книга», все файлы — это отрывки из первой книги, в частности разделы 1, 2 и 3 на латинском, английском и французском.
В своем коде я создаю цикл по разным разделам и объект
Paragraph для каждого языка:
PdfDocument pdfDoc = new PdfDocument(new PdfWriter(dest));
int firstPageNumber = 1;
for (int section = 0; section < 3; section++) {
// latin
addSection(pdfDoc, createParagraph(String.format("./src/test/resources/txt/liber1_%s_la.txt", section + 1)), firstPageNumber, 2);
// english
addSection(pdfDoc, createParagraph(String.format("./src/test/resources/txt/liber1_%s_en.txt", section + 1)), firstPageNumber, 1);
// french
addSection(pdfDoc, createParagraph(String.format("./src/test/resources/txt/liber1_%s_fr.txt", section + 1)), firstPageNumber, 0);
firstPageNumber = pdfDoc.getNumberOfPages() + 1;
}
Мы создаем параграфы
Paragraph следующим образом:
public Paragraph createParagraph(String path) throws IOException {
Paragraph p = new Paragraph();
BufferedReader in = new BufferedReader(
new InputStreamReader(new FileInputStream(path), "UTF-8"));
StringBuffer buffer = new StringBuffer();
String line = in.readLine();
while (null != line) {
buffer.append(line);
line = in.readLine();
}
in.close();
p.add(buffer.toString());
return p;
}
Затем используем созданные параграфы в методе
addSection():
public void addSection(PdfDocument pdfDoc, Paragraph paragraph, int pageNumber, int sectionNumber) throws IOException {
LayoutResult layoutResult;
ParagraphRenderer renderer = (ParagraphRenderer) paragraph.createRendererSubTree();
renderer.setParent(new DocumentRenderer(new Document(pdfDoc)));
while (((layoutResult = renderer.layout(new LayoutContext(new LayoutArea(pageNumber, new Rectangle(36, 36 + ((842 - 72) / 3) * sectionNumber, 523, (842 - 72) / 3)))))).getStatus() != LayoutResult.FULL) {
if (pdfDoc.getNumberOfPages() < pageNumber) {
pdfDoc.addNewPage();
}
layoutResult.getSplitRenderer().draw(new DrawContext(pdfDoc, new PdfCanvas(pdfDoc.getPage(pageNumber++)), false));
renderer = (ParagraphRenderer) layoutResult.getOverflowRenderer();
}
if (pdfDoc.getNumberOfPages() < pageNumber) {
pdfDoc.addNewPage();
}
renderer.draw(new DrawContext(pdfDoc, new PdfCanvas(pdfDoc.getPage(pageNumber)), false));
}
Здесь мы инициализировали объект
ParagraphRenderer и изменили его
LayoutArea согласно параметру
sectionNumber. Мы проверяем статус
LayoutResult и обрабатываем содержимое одной или нескольких страниц, пока не будут готовы все тексты для всех страниц.
Из примера видно, что мы также создаем новую страницу для каждого нового раздела. Это делать необязательно, но латинский текст может быть переведен на английский и французский по-разному, а значит, могут возникнуть серьезные несоответствия, например, когда раздел X с латинским текстом начинается на одной странице, а тот же раздел на английском или французском языках начинается на следующей странице. Поэтому я создаю новую страницу, хотя это и необязательно в таком небольшом примере.