print(tree.find('.//{http://zakupki.gov.ru/oos/types/1}id').text)
# 18934116import re
from lxml import etree
parser = etree.XMLParser(ns_clean=True)
xml = re.sub(' xmlns="[^"]+"', '', xml, count=1) # в xml - ваш реальный xml
tree = etree.fromstring(xml.encode(), parser)
print(tree.find(".//id").text)
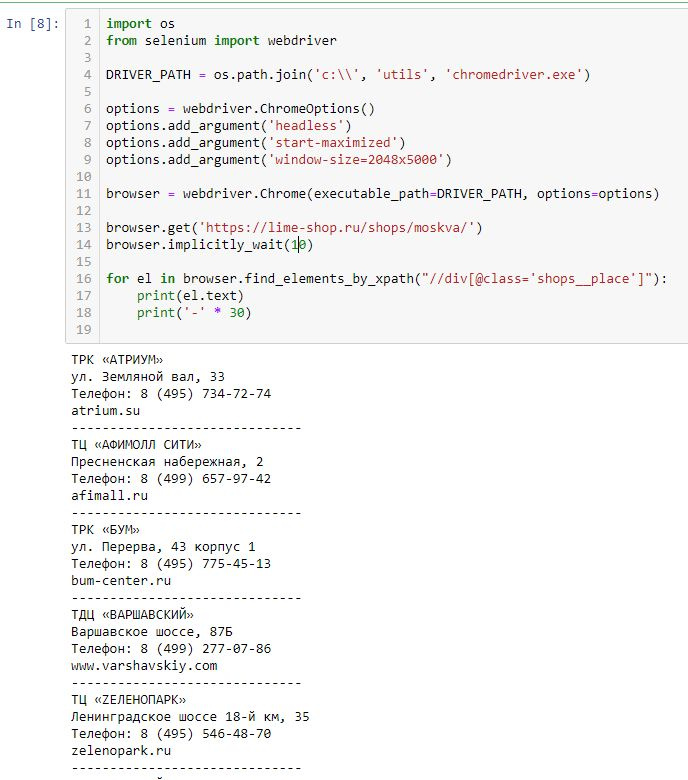
# 18934116import os
from selenium import webdriver
DRIVER_PATH = os.path.join('c:\\', 'utils', 'chromedriver.exe')
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('start-maximized')
options.add_argument('window-size=2048x5000')
browser = webdriver.Chrome(executable_path=DRIVER_PATH, options=options)
browser.get('https://lime-shop.ru/shops/moskva/')
browser.implicitly_wait(10)
for el in browser.find_elements_by_xpath("//div[@class='shops__place']"):
print(el.text)
print('-' * 30)