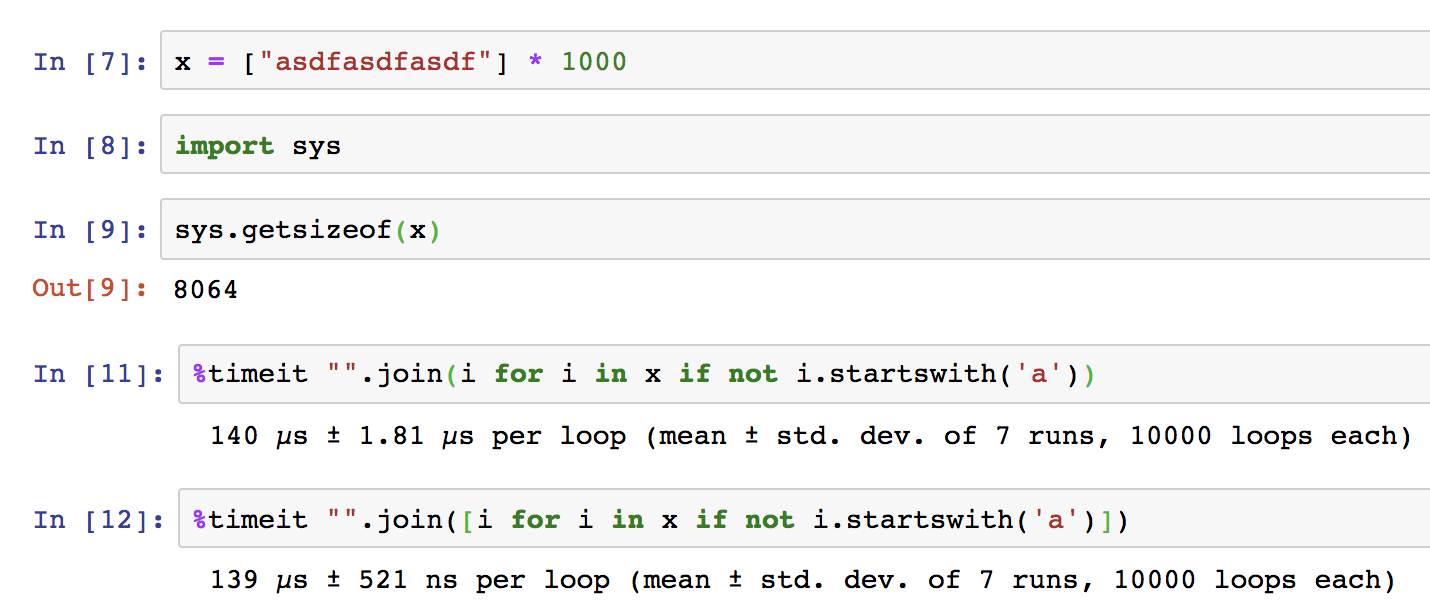
JaxxDexx, на больших? По-твоему, 1000 строк в списке — это большие данные? Или ты собрался в продакшене всегда обрабатывать одну и ту же строку "мой дядя"?)
Вот тебе пример того, что списки ни разу не быстрее генераторов на небольших данных:
Мой вариант будет кушать меньше памяти, а выполняться одно время. Причём, куда стабильней, если ты посмотришь на отклонение.
JaxxDexx, зависит от размера входных данных. Если список слов не будет по размерам превышать размер фрейма стека, который будет хранить генератор, тогда список эффективней. Если я скормлю твоей функции файл с 100гб текста — она загнётся и её убьёт OOM killer. А генератор сожрёт где-то 500 байт оперативы.
JaxxDexx, вообще-то нет, вывернутые наизнанку filter и map без каррирования в питоне ужасны. Списковые включения получше будут. К тому же, startswith эффективней, чем взятие первого элемента и вот эта уродливая конструкция ["М", "м"]
Да, точно, про произвольный доступ я и забыл упомянуть. Хотя, в реальности он мне редко нужен)
Генераторы не только лишь экономят память, но и расходуют её - на кадр персистентного стека, хотя бы
Да, тут полностью согласен, что состояние генератора хранить дороже, чем пару элементов списка. Но когда этот порог памяти переваливает в пользу генераторов? (в среднем, конечно). 100 элементов? 500 элементов?
dollar, у меня больше 10ти разных паролей и их вариаций. То есть вот столько в худшем случае мне нужно попыток на то, чтобы вспомнить. Если через 3 неправильных мне скажут "подождите", то такой сервис просто пойдёт лесом.