Про Гугл спасибо, но там совсем не то, увы. Аналогично в других ПС. Про api также не то и потому, что неизвестно имя и т.д. То есть делать брутфорс по символам это вечность, а там иначе никак. Нет списка кого найти и ники чтобы были хоть примерные.
Интересное предложение, но разгадывание капчи в автоматическом режиме без сервисов и чтобы все были корректно - есть.
Проблемы разгадать капчу никакой нет, поэтому просто купить разгадывание, которое и без того реализовано, увы, не решение проблемы с частым появлением капчи как таковой.
И да, проблема именно в самих прокси, пока свежие все хорошо, но быстро становятся "не вариант", отсюда и вопрос о том, какие взять хорошие прокси или как еще можно решить данный вопрос.
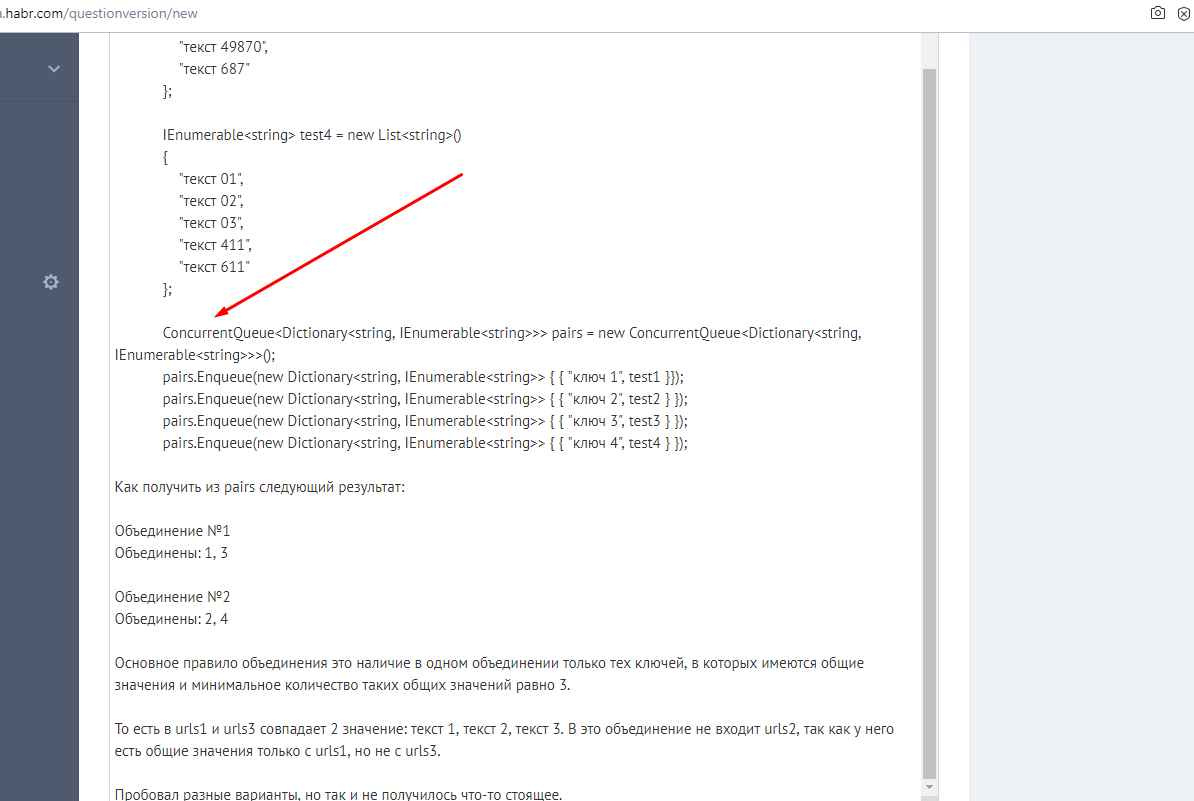
Если обходить с начала в конец, то берется test1 и считается что он маркерный и все остальное сравнить с ним и будет в результате набор объединений, внутри которых не обязательно все элементы содержат одинаковые наборы данных, т.е. минимум 3 совпадения по значениям.
Если так делать, то на первой итерации будет группа
Какой именно убрать помогает понять (тут не знаю точно как это сделать) последующие подобные рассуждения, когда становится видно, что удастся сформировать еще пару только в случае, когда лишний в первой группе будет
И вводных таких наборов данных в плане test может быть любое количество, четное или нечетное как угодно, но на выходе никаких дублей и прочего быть не должно, а что не удается объединить, то будет само по себе по типу объединение содержит 1 элемент ну и пусть.
Для того, чтобы ключи попали в одну группу, требуется наличие у всех них единого набора тех же самых общих данных.
Вариант, когда будут объединения и внутри могут быть элементы, которые не обязательно между собой имеют что-то общее из данных я сделал, там проблем не возникло, а вот с учетом что данные общие обязаны быть вот тут возникла проблема.
#, test1 содержит
"текст 1",
"текст 2",
"текст 3",
test3 содержит
"текст 1",
"текст 2",
"текст 3",
Они объединяются, так как в этой группе у каждого из элементов будет некий набор общих value и число таких value не меньше 3.
test2 содержит
"текст 01",
"текст 02",
"текст 03",
И
test4 содержит
"текст 01",
"текст 02",
"текст 03",
Но если смотреть на сравнение по первому элементу, то можно собрать группу
test1
test2
test3
так как test2 и test3 имеют не менее 3-х общих элементов с test1, только в этой группе все test не будут между собой иметь одинаковый набор элементов, а потому такая группа не будет верной.
Когда я редактирую вопрос у меня все данные показываются четко. Издеваться мне неинтересно и лучше умет общаться, а не такое писать, когда в редакторе одно, а тут почему-то другое, я не знаю как это править иначе.
profesor08, спасибо за совет, но тут речь исключительно и только про парсинг выдачи Гугл т.е. делает запрос по типу https://www.google.com/search?q=вопрос и в какой-то момент Гугл отдает рекапчу v2. Ее решает сервис и возвращает токен, я его отправляю по адресу вида https://www.google.com/sorry/index?q=специальный параметр как получить известно&continue=урл куда перенаправить когда все ок&g-recaptcha-response=токен. И в ответ на данный post запрос должен быть редирект и далее получение куки, но этого нет и идет неприятное сообщение, которое говорит о не прохождении капчи но ТОЛЬКО на поиске, никаких других сайтов тут нет.
Ставить вручную, получать и после ставить и другие варианты тут не срабатывают.