longclaps, хочу купить. Если прирост реально в разы, то жду 2070. Если как в играх (15-30%), то есть хороший вариант (точно из игрового ПК) 1080 за 25к.
Роман, наверно 10к*30к+30к*10=итого 300 Мб
300*4байта=1,2 Гб
мниста имеет 50к строк, это мой пример до 500к.
Остаётся вопросом - в память грузятся минибатчи или "всё что влезет"?
И это всё прикидка на глазок... может у вас есть возможность запустить к примеру msi afterburner и обучение мниста, и посмотреть сколько реально съедается видеопамяти?
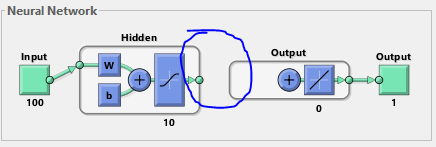
Столкнулся с проблемой. Если подаю при обучении сети только "эталонные" данные, на которые нужно реагировать, то сеть выдаёт вот такой рисунок структуры сети и не хочет обучаться. Собственно поэтому и возник вопрос. Какие данные нужны для обучения и к какому типу сети применять? Пока что всё пробую в матлабе.