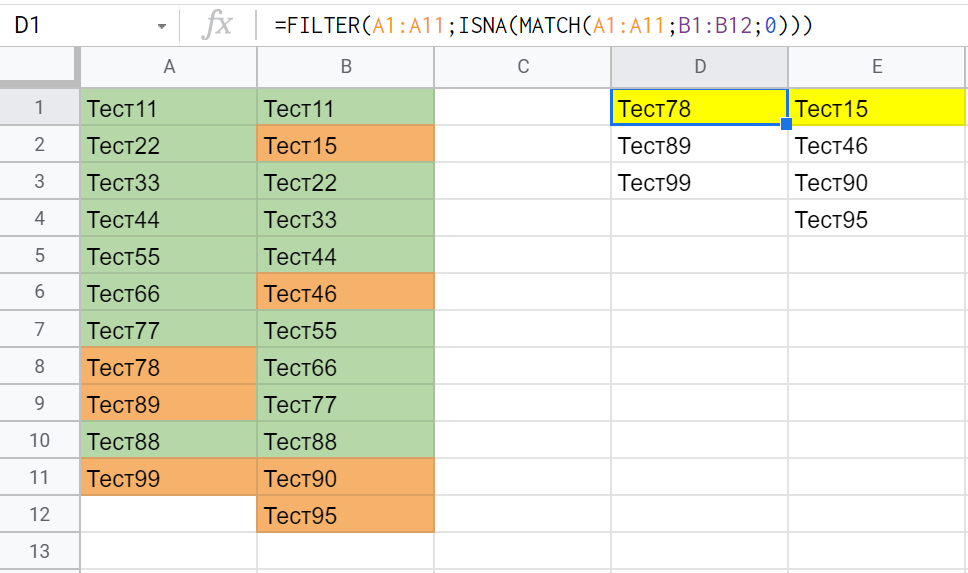
Есть два столбца с текстовыми списками. Нужно найти в первом столбце значения, которые не повторяются во втором, и параллельно найти значения из второго, которые не повторяются в первом. То есть найти различия в списках. Затем нужно вывести результат в отдельный диапазон ячеек - найденные уникальные значения из первого списка в один столбец, а из второго - во второй:

Пробовал сделать всё при помощи условного форматирования с формулой
=СЧЁТЕСЛИ($A:$B;A1)<2
с последующей фильтрацией списка по цвету заливки, но на это уходит много ручной работы. Есть ли способ реализовать это как-то по-другому при помощи формулы фильтра или чего-то подобного?
Заранее благодарю!