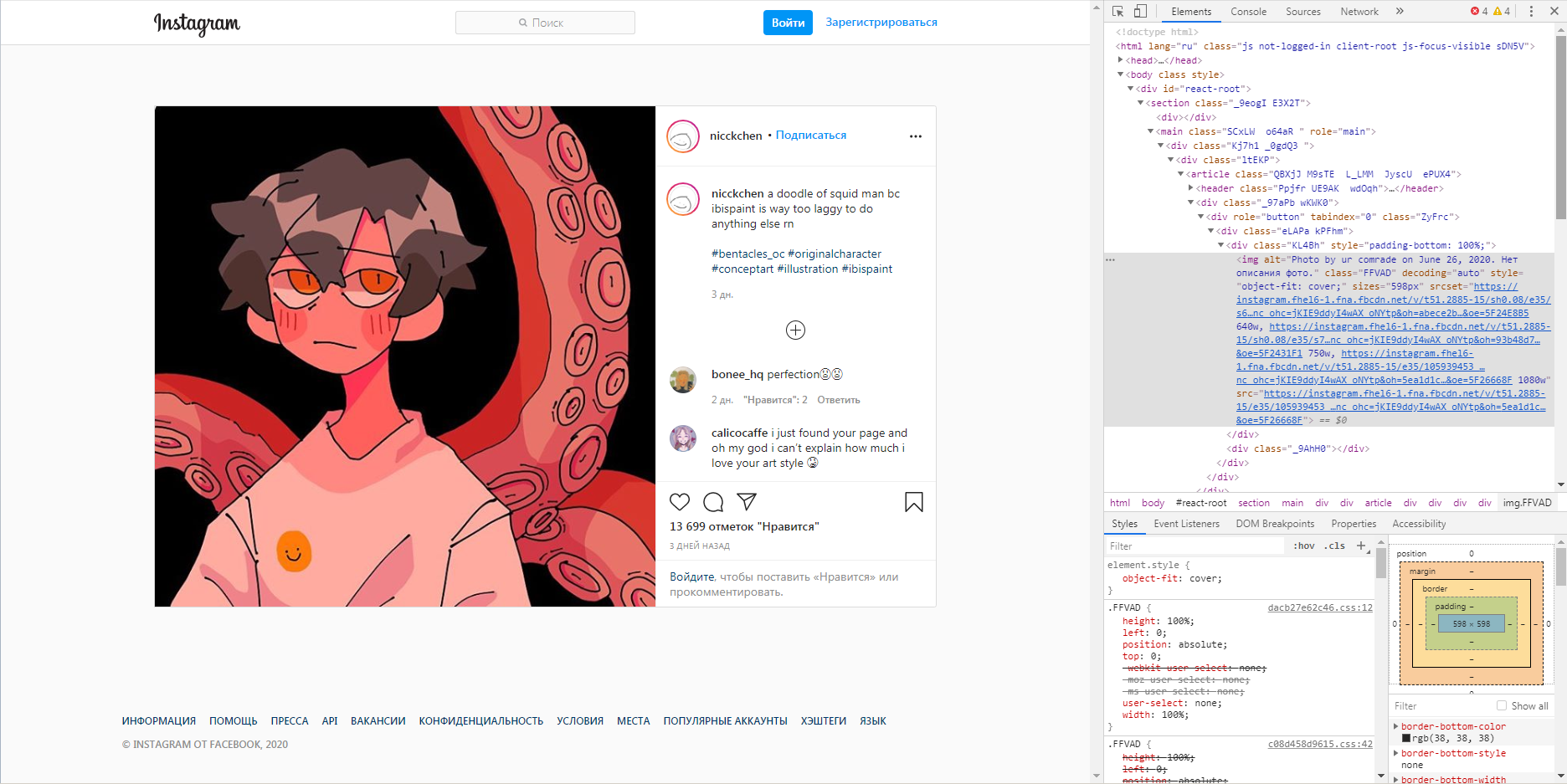
В инстаграмме при просмотре кода элемента нужная мне ссылка лежит в , но в просмотре кода страницы она есть, но лежащие друг в друге отсутствуют, почему так происходит и можно ли получить код страницы в таком же формате как и код элемента?
from bs4 import BeautifulSoup
import requests
import re
link_to_video = input('link: ')
link = link_to_video.split('?')[0] + '?__a=1'
response = requests.get(link_to_video).text
soup = BeautifulSoup(response, 'lxml')
for heading in soup.find_all(re.compile("^script")):
if heading.text.strip()[0:18] == 'window._sharedData':
arr_link = heading.text.strip('window._sharedData = ').split('video_url')[1].split('"')[2].strip().split('\\u0026')
url = ''
for i in arr_link:
url += i + '&'
print(url)
Очень много костылей, логика работы такая:
Заходишь в браузер и вводишь: ссылка на пост, все что после ? удаляешь и вместо этого ставишь:
?__a=1
Заходишь и ищешь ссылку на картинку.
Потом делаешь запрос через реквесты, и понимаешь что в ответ получаешь не то что хотел, ссылка генерируется через изменение DOM посредством js. Парсишь все теги script через bs4 и получаешь что-то примерно 10 тегов. Как я понял, нужная тебе информация находится в теге, который найчинается на
window._sharedData =
С помощью for перебрал все теги и получив нужный, обрабатываешь строку, т.к. json.loads возвращает ошибку.
Если сможешь улучшить скрипт, убрав или упростив костыли, дай знать.
def get_image_from_url(url):
session = requests.session()
request = session.get(url=url, headers=headers)
if request.status_code == 200:
soup = bs(request.content, 'lxml')
try:
soup = str(soup)
index = soup.find("accessibility_caption")
soup = soup[index-1000:index]
end = soup.rfind('\",\"')
start = soup.rfind('{') + 8
link = soup[start:end]
link = link.replace('\\u0026', '&')
img = requests.get(link)
except Exception as e:
print(e)
else:
print(request.status_code)
print('ERROR')
return img.content
После ссылок на фото присутствует заголовок "accessibility_caption" в котором указан username загрузившего фото и краткая информация от алгоритмов инстаграмма по типу на фото изображены люди, небо, машины. И каждая ссылка заключена в {} и в конце информация по высоте и ширине фото. Я просто беру последние фигурные скобки перед заголовком, обрезаю от них эту информацию, перехожу по получившейся ссылке и возвращаю картинку


 Простой
Простой