Приветствую. Вот подробнее распишу, не знаю как загуглить.
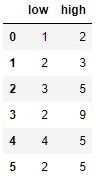
Есть таблица:
a = [[1,2], [2,3], [3,5], [2,9], [4,5], [2,5]]
df = pd.DataFrame(a, columns=['low', 'high'])
df
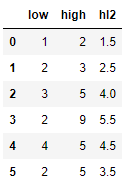
Без проблем получается посчитать среднее между колонками
df = df.assign(hl2 = (df.low + df.high) / 2)
df
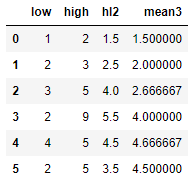
А вот как посчитать среднее для каждых последних 3х строк?
Попробовал так:
df = df.assign(mean3 = df.tail(3).hl2.mean())
df
И получил везде результат в общем по последним 3м строкам

Можно конечно перебрать циклом, но при больших данных это очень не эффективно. Думаю должен же быть какой-то нативный метод для этого?
Например в системе мониторинга prometheus используется метод в запросе rate, который делает нечто подобное.