Как сохранить точные копии относительных ссылок командой wget?
Есть один сайт, который нужно скопировать локально, но при этом необходимо сохранить точную копию относительных url адресов. Все посты заканчиваются на .html, но после скачивания, в браузере получаем "index.html@p=134.html". Что нужно добавить в эту команду wget -r -k -l 3 -p -E -nc, чтобы получить точную копию относительных ссылок в браузере? Убирал -k, добавлял и отбавлял различные команды - не помогло. Перерыл буквально все, так и не понял, как скачать точную копию с сохранением точных ссылок. Подскажите, пожалуйста, в чем дело. Не обязательно чтобы все файлы открывались в браузере, например, файлы, которые без расширения.
Можно пример команды для страниц? Если сайт имеет посты с расширением .html, а все остальное без расширения. У меня -k (-convert-links) в конце работы все преобразовывает в "index.html@p=134.html". Как запретить ему это делать?
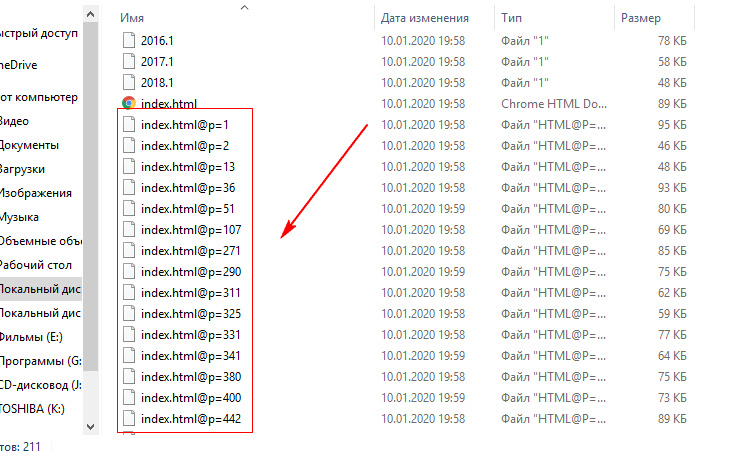
По окончании скачивания в index.html ссылки преобразовываются вида "index.html@p=", и создаются копии файлов под этим же именем. Почему так происходит, где копать, что читать. Может направите в нужную сторону?
dimonchik2013, вопрос же не в файлах. Параметры команды: "wget -l 9 -rkpE -A html" - я так понимаю, расширение .html тут указывать не верно? После такой команды, все страницы преобразовываются в ненужный мне вид, выше уже писал - как отменить это. Отменить преобразование index.html@p=" Я так понимаю, вся проблема в -k? Как вы скачиваете страницы?
Когда в браузере открываешь index.html, все ссылки (особенно постовые) на странице при наведении ссылаются на эти копии файлов. Если кратко - меня не устраивают относительные ссылки вида "index.html@p=271". Мне нужна точная копия сайта, с нормальными url адресами, а не то, что показано на изображении. Например, исходный url такой - /name_post.html, после скачивания рекурсивно через wget получаем то, что на скриншоте.
Надеюсь, так понятно? Т. е., проблема не в css и других файлах.