Категорически приветствую, прошу направить на путь, какими инструментами и фреймворками воспользоваться для оптимизации рутинных задач, желательно посредством python на уровне дилетанта или возможно другими готовыми средствами, где почитать подробней.
Проблема:
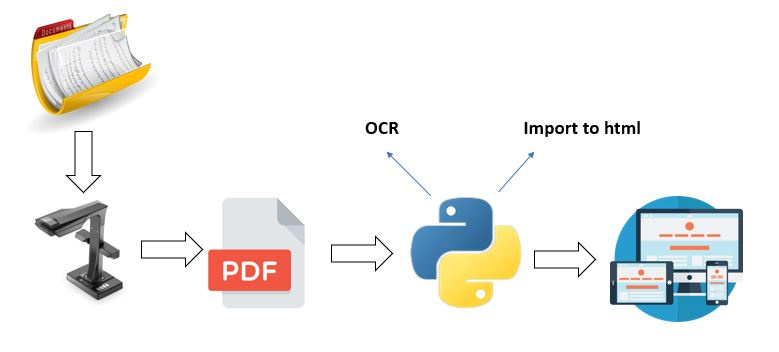
Есть огромное количество оцифрованных документов, которые необходимо распознать (пробовал с помощью TesseractOCR, безуспешно) в автоматическом режиме по определенным полям и внести на сайт-форму, не имея при этом доступ к бд.
Вопрос:
Прошу лишь познакомить с аналогичным экспириенсом как распознать по меткам документ, экспортировать в из cvs/exel etc, а потом в html форму.