
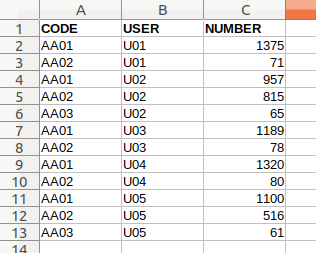

CODE,USER,NUMBER
AA01,U01,1375
AA02,U01,71
AA01,U02,957
AA02,U02,815
AA03,U02,65
AA01,U03,1189
AA02,U03,78
AA01,U04,1320
AA02,U04,80
AA01,U05,1100
AA02,U05,516
AA03,U05,61#!/usr/bin/env python3
import csv
import json
table_file = '/home/ratkin.roman/Документы/test.csv'
new_table = {}
with open(table_file, 'r', encoding='utf-8') as table:
f = csv.reader(table, delimiter=',')
next(f)
for row in f:
new_table.setdefault(row[1], {}).update([(row[0],row[2])])
print(json.dumps(new_table, sort_keys=True, indent=4)){
"U01": {
"AA01": "1375",
"AA02": "71"
},
"U02": {
"AA01": "957",
"AA02": "815",
"AA03": "65"
},
"U03": {
"AA01": "1189",
"AA02": "78"
},
"U04": {
"AA01": "132",
"AA02": "80"
},
"U05": {
"AA01": "1100",
"AA02": "516",
"AA03": "64"
}
}
from itertools import groupby
source = [
{'code': 'AA01', 'group': 'U01', 'user': '1375', },
{'code': 'AA01', 'group': 'U01', 'user': '1575', },
{'code': 'AA03', 'group': 'U02', 'user': '1375', },
{'code': 'AA02', 'group': 'U02', 'user': '1345', },
{'code': 'AA02', 'group': 'U03', 'user': '1315', },
{'code': 'AA01', 'group': 'U04', 'user': '1615', },
]
result = {k:list(v) for k,v in groupby(source, lambda x: x['group'])}
>>> print(result)
{'U01': [{'code': 'AA01', 'group': 'U01', 'user': '1375'}, {'code': 'AA01', 'group': 'U01', 'user': '1575'}], 'U02': [{'code': 'AA03', 'group': 'U02', 'user': '1375'}, {'code': 'AA02', 'group': 'U02', 'user': '1345'}], 'U03': [{'code': 'AA02', 'group': 'U03', 'user': '1315'}], 'U04': [{'code': 'AA01', 'group': 'U04', 'user': '1615'}]}
>>> result = {k:{row['user']: row['code'] for row in v} for k,v in groupby(source, lambda x: x['group'])}
>>> result
{'U01': {'1375': 'AA01', '1575': 'AA01'}, 'U02': {'1375': 'AA03', '1345': 'AA02'}, 'U03': {'1315': 'AA02'}, 'U04': {'1615': 'AA01'}}
>>>
from itertools import groupby
source = [
{'code': 'AA01', 'group': 'U01', 'user': '1375', },
{'code': 'AA01', 'group': 'U01', 'user': '1575', },
{'code': 'AA03', 'group': 'U02', 'user': '1375', },
{'code': 'AA02', 'group': 'U02', 'user': '1345', },
{'code': 'AA02', 'group': 'U03', 'user': '1315', },
{'code': 'AA01', 'group': 'U04', 'user': '1615', },
]
result = {}
for key, group in groupby(source, lambda x: x['group']):
subgroup = {}
for item in group:
subgroup[item['code']] = item['user']
result[key] = subgroup{
'U01': {'AA01': '1575'},
'U02': {'AA03': '1375',
'AA02': '1345'},
'U03': {'AA02': '1315'},
'U04': {'AA01': '1615'}
}