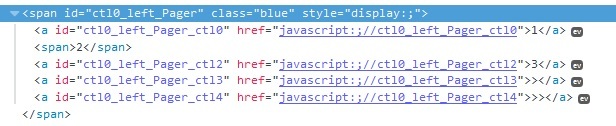
Разрабатывая парсер столкнулся с проблемой парсинга динамических страниц, точнее перехода по ссылкам пагинации, которые имеют вид как на скриншоте:
 А в качестве запроса передают след. данные:
А в качестве запроса передают след. данные: 
После клика по номеру страницы контент на странице подменяется, адрес в браузере не меняется, при этом селекторы пейджеров имеют не совсем логичные имена, по-этому нельзя определить их промежуток.
UPD: если это важно. Ответом приходят кусок готового HTML, который полностью подменяет нужную мне таблицу данных вместе с пейджерами.
Если честно мне не совсем понятно как сделать обход такой пагинации. Пытался гуглить, смотрел статьи, уроки, но везде говорится о парсинге более простых AJAX-запросов, где намного проще составить запроса для парсинга.





